ADALab Program at ACM SIGMOD 2019
ACM SIGMOD is the premier conference for research on data management and data systems. And at SIGMOD 2019, the students, alumni, and friends of the ADALab are staging an impressive presence. This post gives an overview of the papers and demos from my research group at SIGMOD and how they are intellectually connected. It also acts as a one-stop shop for the ADALab program at SIGMOD. For starters, here are some salient statistics:
- 4 full research papers: Krypton, MorpheusFI, Tuple-Oriented Compression, and Nimbus.
- 2 demonstrations: SpeakQL and Nimbus
- 2 workshop papers at DEEM: Cerebro and MLDataPrepZoo
- 5 speakers: Side Li, Supun Nakandala, and Vraj Shah (UCSD students); Lingjiao Chen and Fengan Li (UW-Madison alumni)
- 1 student research competition entry: Vraj Shah on SpeakQL
- 2 awards: Best Paper Honorable Mention (Krypton) and distinguished PC service award
I will shortly offer vignettes on all of our papers. But we first start with a birds-eye view of how these papers fit into ADALab’s research focus on advanced data analytics (ADA), at the intersection of ML and data systems.
ADA Lifecycle and our SIGMOD Presence
As illustrated below and elaborated in a recent textbook I co-authored, we split the ADA/ML application lifecycle into three main stages: Source, Build, and Deploy.
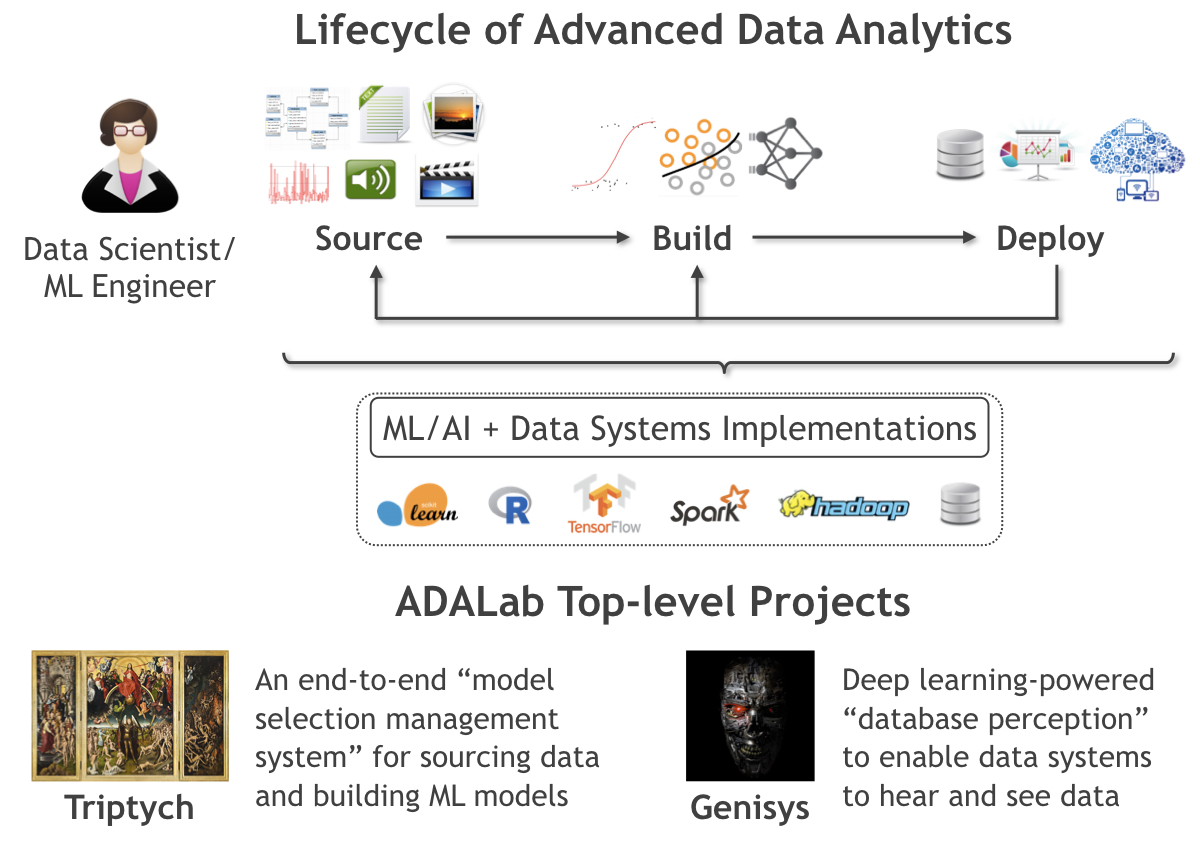
Source is the stage of procuring, organizing, and preparing data for ML. Build is the stage of crafting prediction functions using the data. Deploy is the stage of integrating prediction functions with the data application. Throughout this lifecycle, bottlenecks arise for both resource efficiency and human productivity. ADALab’s research systematically tackles such bottlenecks to make it easier, faster, and cheaper for data applications to exploit ML.
Our research is organized under two top-level projects: Triptych and Genisys. Triptych targets the Source and Build stages in general. Genisys primarily targets the Deploy stage for unstructured data. They are not disjoint but such an organization helps us streamline our research efforts due to the differing flavors of technical challenges and systems concerns across the stages. For instance, Source and Build are usually offline, while Deploy is usually online. Within this intellectual framework, here is how our presence at SIGMOD 2019 has shaped up (download PDF here).
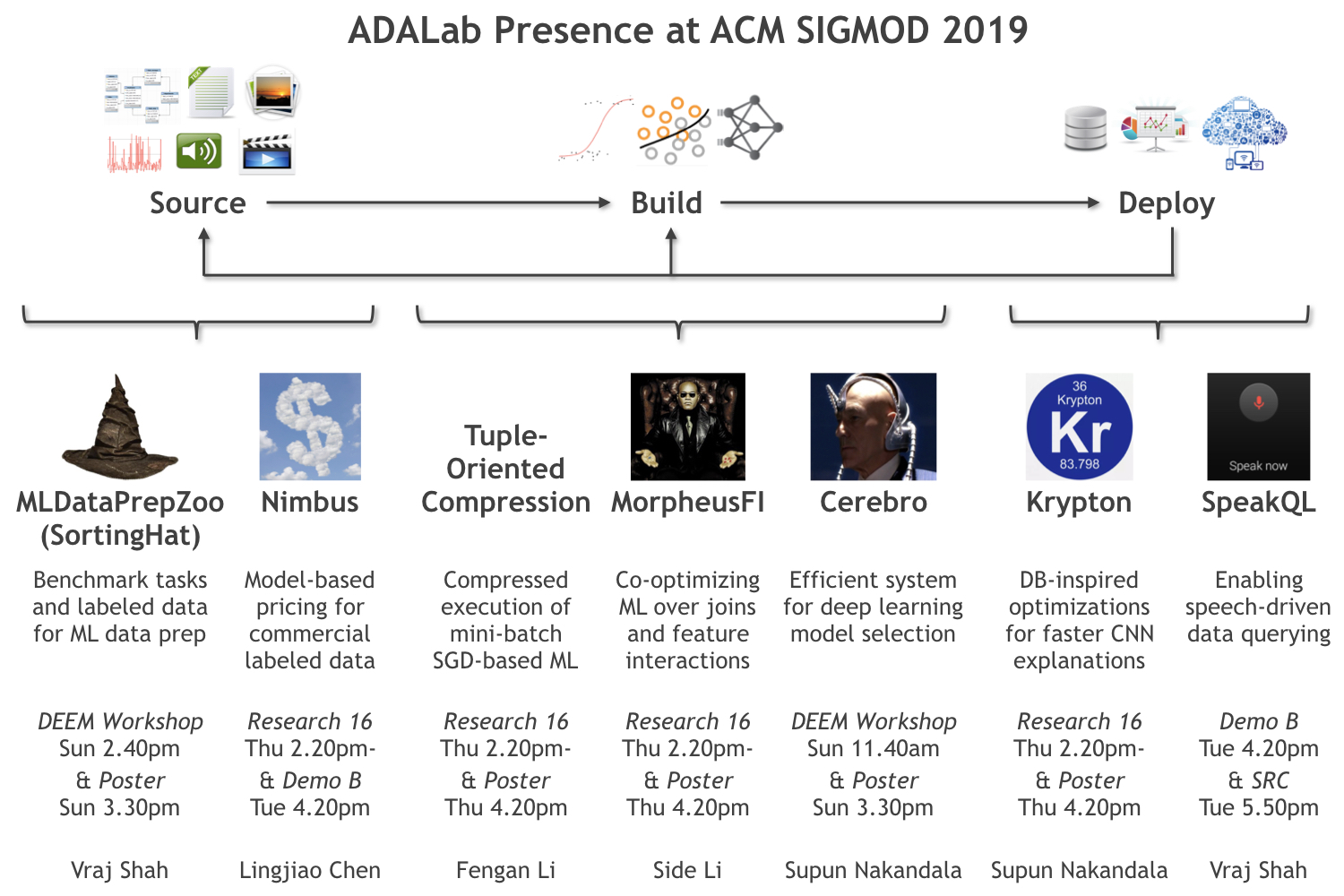
Overview of ADALab Papers at SIGMOD 2019
ML Data Prep Zoo. Paper. Project webpage.
Data preparation (prep) time is a major bottleneck for ML, especially on structured data. While emerging AutoML frameworks claim to automate data prep too, the quality of their automation is unclear. This paper presents our vision of a “zoo” of integrated benchmark task definitions for ML data prep, as well as large labeled datasets and pre-trained ML models to (semi-)automate such tasks. We believe our labeled datasets and pre-trained models can help reduce the manual effort of the Source stage, while also helping improve the quality of AutoML frameworks.
Blog post: Vraj explains our vision, including our progress on the first task of ML feature type inference (Project SortingHat), in this post.
Impact: Google has expressed interested in integrating our models with TensorFlow Data Validation.
Nimbus. Paper. Demo Paper. Project webpage.
Labeled datasets are becoming commodities traded via data markets. While current markets focus only on selling data, we envision markets selling ML models trained on commercial labeled data to enable new accuracy-price tradeoffs for buyers and to let sellers reach new customer segments. This paper presents the formal foundations and the first practical mechanisms for such “model-based pricing” of data. We believe such a market can obviate the Source stage for some non-technical ML users because after all, data is sometimes only a means to an end in an ML application.
Collaborator: Paris Koutris (UW-Madison).
Tuple-Oriented Compression (TOC). Paper.
Data compression and compressed query execution is common in columnar RDBMSs. But little work has studied the potential of such execution for ML training “queries.” This paper offers the first compression scheme tailored to the access patterns of mini-batch SGD-based ML. Inspired by LZW text compression, it presents new data structures and compressed execution algorithms that offer significant runtime speedups for the Build stage. As dataset sizes keep growing, we believe compressed ML execution will become more common in ML systems.
Collaborators: Jignesh Patel (UW-Madison), Jeff Naughton (Google), and Xi Wu (Google).
Blog post: The SIGARCH folks beat us to the punch with this gracious post!
Fun fact: This is the 4th version following rejects from VLDB’17, SIGMOD’17, and ICML’18. Fengan’s work is an inspirational study in persistence!
MorpheusFI. Paper. Project webpage.
Relational datasets are often multi-table but most ML tools assume single-table inputs. This forces ML users to materialize joins, wasting resources and slowing analysis. “Factorized ML” avoids this by pushing ML through joins; Morpheus generalized this idea to any ML procedure written in bulk linear algebra but it is limited by linearity over features. This paper generalizes Morpheus to support non-linear feature interactions in factorized linear algebra. It accelerates the Build stage by optimizing two common feature engineering operations in statistical ML.
Fun fact: Born out of Side’s BS honors project, this is the first ever paper at SIGMOD by a UCSD undergrad!
Impact: Side’s Python tool was explored for production use by a Russian e-commerce company.
Cerebro. Paper. Project webpage.
Training deep nets requires a highly empirical model selection process to configure data representation, model architecture, and hyper-parameters. ML users often try dozens of configurations. Alas, most ML systems focus on scaling only one training configuration at a time, wasting system resources and/or sacrificing reproducibility. This paper presents a new SGD-oriented parallelism paradigm to raise the resource efficiency of this process while ensuring reproducibility. We believe it can help democratize the Build stage of deep learning.
Blog post: Supun and Yuhao talk more about Cerebro in this post.
Impact: Pivotal has expressed interest in integrating Cerebro into Greenplum and MADlib. Cerebro is also helping behavioral health scientists at UCSD use deep nets to get a deeper understanding of daily exercise activities and their impact on health.
Krypton. Paper. Project webpage.
Deep CNNs are popular for image analysis in many domains. Because CNNs are effectively black boxes, “explanations” of their predictions are often sought by many domain users. Occlusion-based explanation (OBE) is a popular mechanism for this purpose. OBE hides patches of the image to re-predict the output and yields a heatmap over the pixels. Alas, OBE is highly compute-intensive. This paper casts OBE as a query optimization problem and presents techniques combining database-inspired optimizations and vision science to make OBE faster. This project is part of our “database perception” vision for the Deploy stage of deep learning for unstructured data.
Collaborator: Yannis Papakonstantinou (UCSD).
Blog post: Supun talks more about Krypton in this post.
SpeakQL. Demo Paper. Project webpage.
Automatic speech recognition (ASR) is now highly accurate due to deep learning, raising the popularity of spoken interactions on tablets, smartphones, and conversational assistants. This project studies the implications of this trend for structured data querying on such devices. The first stage focuses on a tractable but useful subset of regular SQL that is aimed at data professionals that seek more flexible anytime-anywhere access to their data. This demo will let the audience play with SpeakQL 1.0 and learn about the challenges in building such a system. This project is also part of our “database perception” vision for the Deploy stage of deep learning for unstructured data.
Collaborators: Lawrence Saul (UCSD).
Blog post: Vraj talks more about SpeakQL in this post.
Fun fact: The SpeakQL demo includes a competition on who can speak correct SQL fastest. Database aficionados, bring your A-game! :)
Overall, I feel incredibly fortunate to work with (or have worked with) such a splendid cohort of creative and productive students. I may be going out on a limb but I believe our presence is likely the largest ever at a SIGMOD/VLDB by an academic’s research group. Apart from the hard work of my students and collaborators, another key reason for this is the extra thorough and fair PC process this year thanks to the terrific efforts of Natassa Ailamaki, the PC chair.
I would also like to thank all past and present sponsors of ADALab’s research. We are firing on all cylinders in our quest to better understand, characterize, and improve all stages of the ADA lifecycle. Watch this space for both more research publications, more open source software, and more dataset releases from us in the near future.

Finally, a shout out to our UCSD friends at SIGMOD 2019. Two of Alin Deutsch’s students/alumni also have full research papers there: Rana Alotaibi and Vicky Papavasileiou. Rana’s paper proposes a new query rewriting mechanism and optimizations for polystore systems. Vicky’s paper proposes a new declarative language and mechanisms to capture and query provenance in scalable graph analytics.
All in all, UCSD’s Database Lab has an impressive set of 6 full research papers at SIGMOD 2019, tied for the highest by an academic database group; see full list here. And we are tied with none other than UW-Madison (my alma mater). I am certainly looking forward to the customary group photos with both the UCSD and UW-Madison contingents (armies?) at Amsterdam! :)