Using ML to automate data prep for ML
This post is about our new line of project(s) that aims to automate data preparation (prep) for ML. I’m presenting a workshop paper at DEEM, SIGMOD 2019 titled The ML Data Prep Zoo: Towards Semi-Automatic Data Preparation for ML. It is co-authored with my advisor, Arun Kumar.
Introduction
Data preparation (prep) still remains a major bottleneck for building any real-world ML application. Several surveys of data science practitioners have shown that the time spent in data prep can go as high as 80% of their time. Cloud companies have released AutoML platforms such as Google’s AutoML Tables and Salesforce’s Einstein that automates the entire ML pipeline, everything from preparing the data, picking the right features, choosing ML algorithms, to tuning the knobs of these algorithms. Unfortunately, there does not exist any benchmarks to quantify the goodness of automation for data prep in these AutoML platforms. This would require formalizing the major data prep steps and create benchmark labeled datasets to standardize their evaluation.
 Most importantly, the key limiting factor to achieve data prep automation is not ML algorithmic advances, but the availability of large high-quality datasets. For instance, Google’s Inception architecture that achieved human-level accuracy in the task of object classification used a variant of the CNN. The algorithm was proposed way back in 1989. However, the model was trained on the ImageNet dataset corpus of approximately 1.5M images, which was made public in 2009. In just a few years, the availability of the high-quality image dataset lead to advancement in several image recognition tasks.
Most importantly, the key limiting factor to achieve data prep automation is not ML algorithmic advances, but the availability of large high-quality datasets. For instance, Google’s Inception architecture that achieved human-level accuracy in the task of object classification used a variant of the CNN. The algorithm was proposed way back in 1989. However, the model was trained on the ImageNet dataset corpus of approximately 1.5M images, which was made public in 2009. In just a few years, the availability of the high-quality image dataset lead to advancement in several image recognition tasks.
In this line of project(s), we aim to objectively quantify the key data prep tasks by creating a common understanding of them, understand why exactly these tasks are hard to automate and create benchmark labeled datasets for them. Our focus is on relational data. Such datasets are typically stored with DB schemas in relational database management systems or as CSV or JSON files. A typical data prep workflow is shown below.
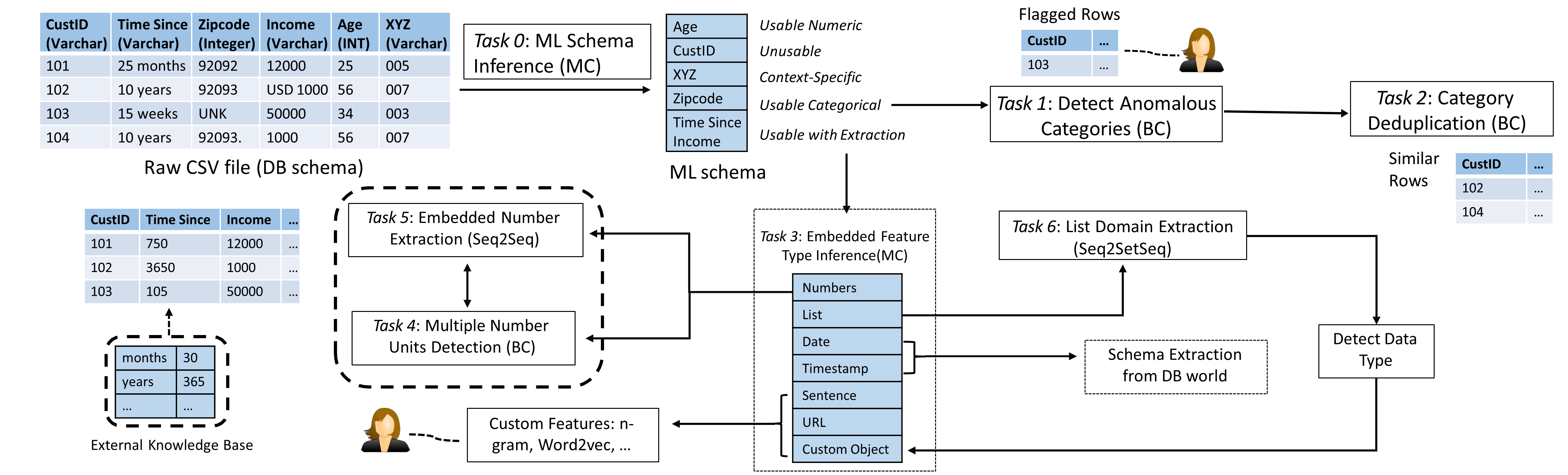
Case Study: ML Feature Type Inference
The very first data prep step is to infer the ML feature types (or the ML schema) from the DB schema. For instance, age is a numeric feature and zipcode is categorical. Attributes such as time since and income have numbers embedded in them, which requires some form of extraction to be useful as a feature. This task is hard to be automated because there exists a semantic gap between the DB schema and the ML schema. The DB schema is syntactic: it tells us the data type of a column such as an integer, real, or string. On the other hand, the ML schema is semantic: it tells us what type of feature a column is. For instance, ZipCodes are usually stored as integers, but it is a categorical feature. However, a syntactic tool like Python Pandas will treat it as a numeric feature, which can lead to nonsensical results.
 To bridge this semantic gap, we cast this data prep task as an ML classification problem. To do this, we need the following 4 things.
To bridge this semantic gap, we cast this data prep task as an ML classification problem. To do this, we need the following 4 things.
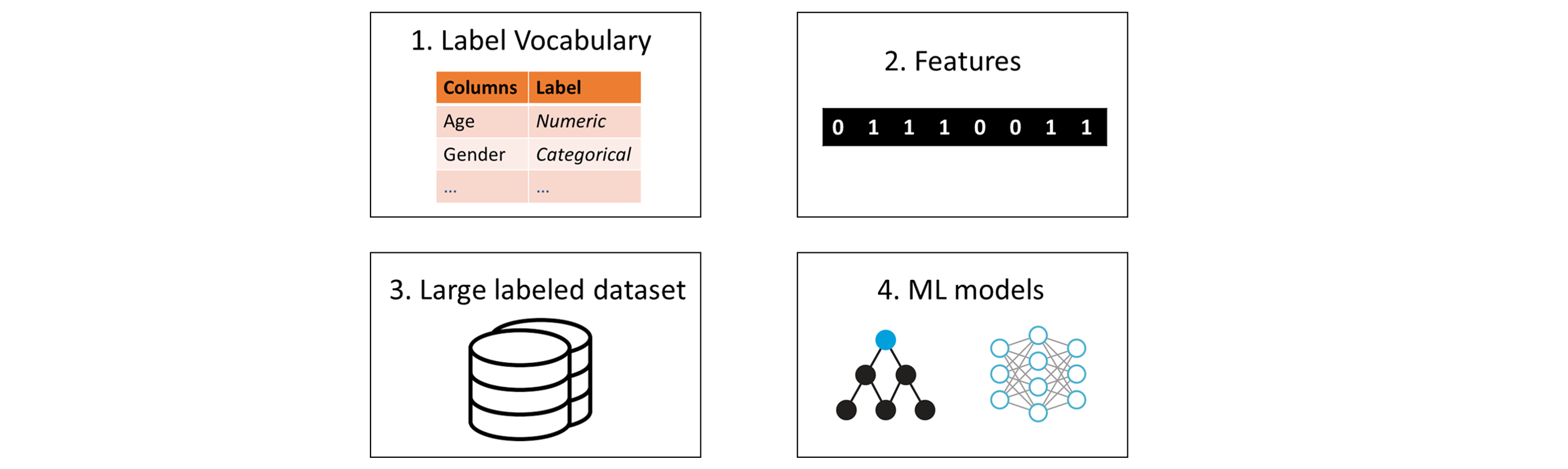
Label Vocabulary
There is usually not enough information in just the raw data file to identify the class (numeric or categorical ) correctly. Consider the following example.
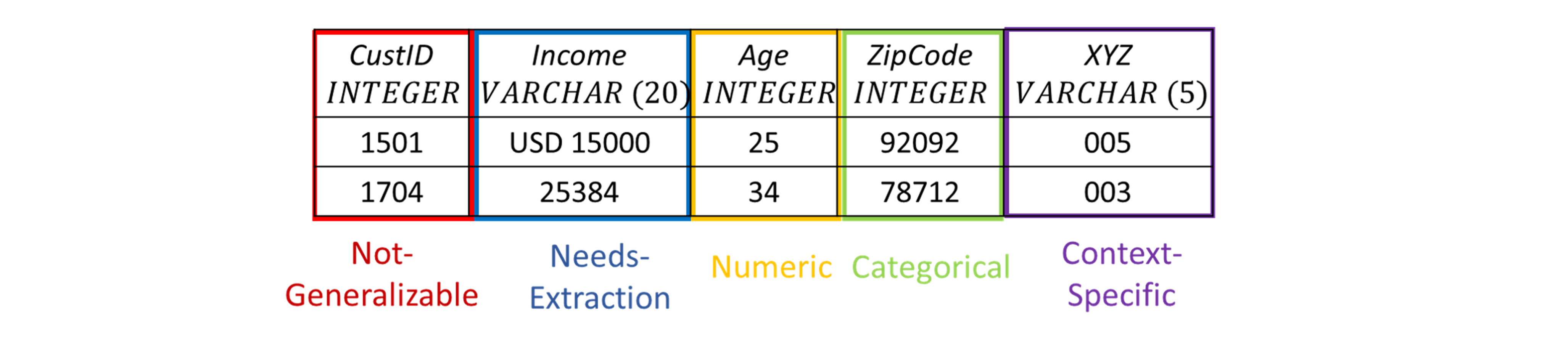 (1) Income is actually a numeric feature but some of its values have a string prefix, which requires extraction of values. (2) CustID is unique for every customer, hence it can not be generalized for ML. (3) Inspecting only the column XYZ, it is difficult to decide if the feature is numeric or categorical. Thus, we created an intuitive 5-class prediction vocabulary by considering 3 more classes to captures different variety of columns.
(1) Income is actually a numeric feature but some of its values have a string prefix, which requires extraction of values. (2) CustID is unique for every customer, hence it can not be generalized for ML. (3) Inspecting only the column XYZ, it is difficult to decide if the feature is numeric or categorical. Thus, we created an intuitive 5-class prediction vocabulary by considering 3 more classes to captures different variety of columns.
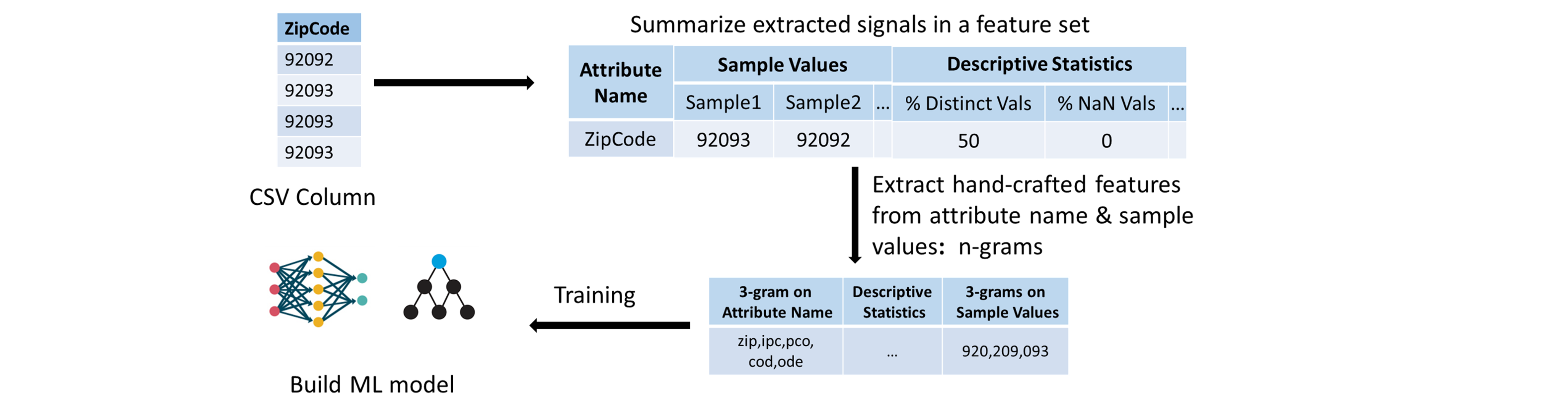
Features
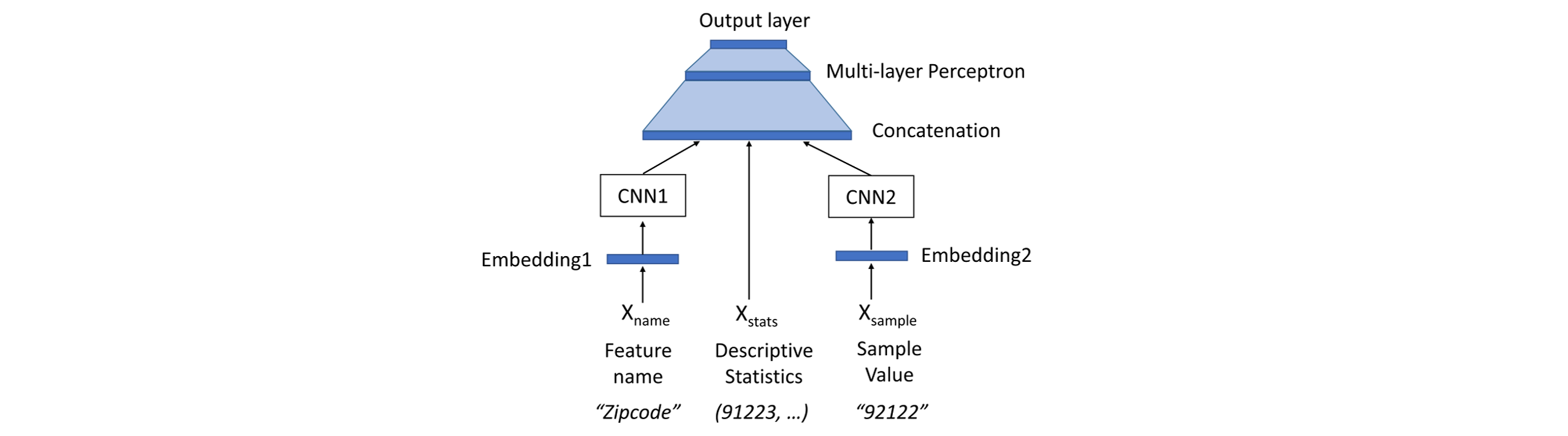
We replicate the human-level intuition into ML models by extracting signals from the raw CSV files that a human reader would look at. Given a column, to identify the feature type, a human reader would look at the attribute (or column) name, some sample values in the column and even descriptive statistics about the column such as the number of NaNs or number of distinct values. For instance, just by inspecting the attribute name such as ZipCode, an interpretable string, a human would know that the feature type is categorical. We extract these signals from the raw column and we summarize them in a feature set, which we use to build popular ML models.
Labeled Dataset
We obtain over 360 real datasets from several sources such as Kaggle and UCI ML Repo. Each column of the CSV file is just one example for our ML task. We collected over 9000 such examples and manually labeled them into either of the classes. This process took about 75 man hours across 4 months.
ML models
We use our feature set on our labeled dataset to build ML models. We compare several ML approaches such as logistic regression, support vector machine with radial basis kernel, Random Forest, k-nearest neighbor (k-NN) and a character-level convolutional neural model. The architecture of the neural model is shown below.
Results
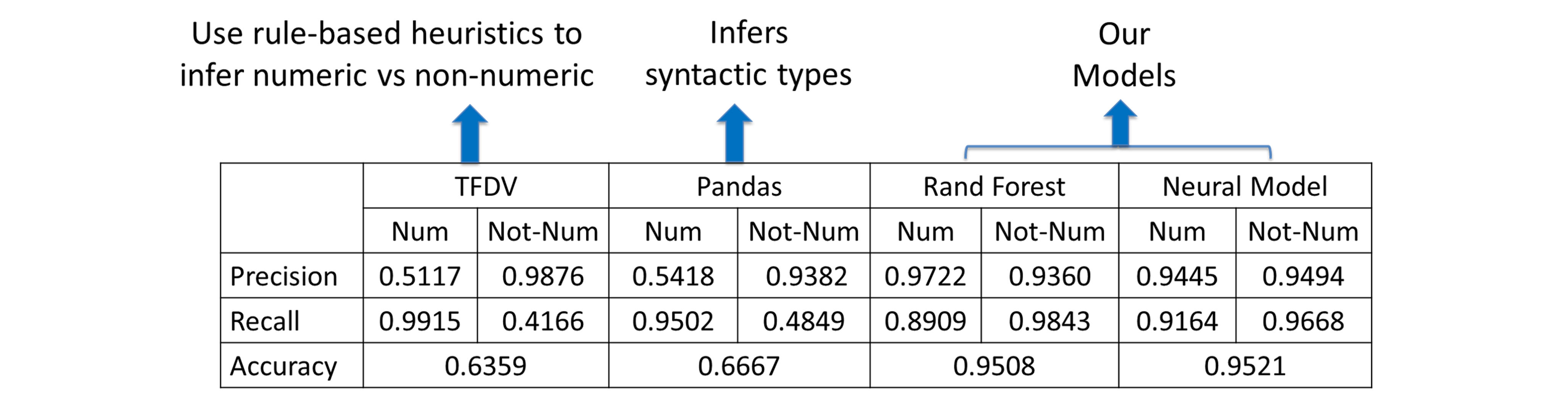
We compare our approach with the existing tools: TFDV and Pandas. TFDV is a tool for managing ML-related data in TensorFlow Extended. It uses heuristic rules to infer ML feature types. Python Pandas can only infer syntactic types: int, float, and object. Hence, we can not use our 5-class vocabulary for comparison. Instead, we reduce the number of classes and report the results on numeric vs. non-numeric. We notice a massive lift of 30% in accuracy for our approach against both TF-DV and Pandas.
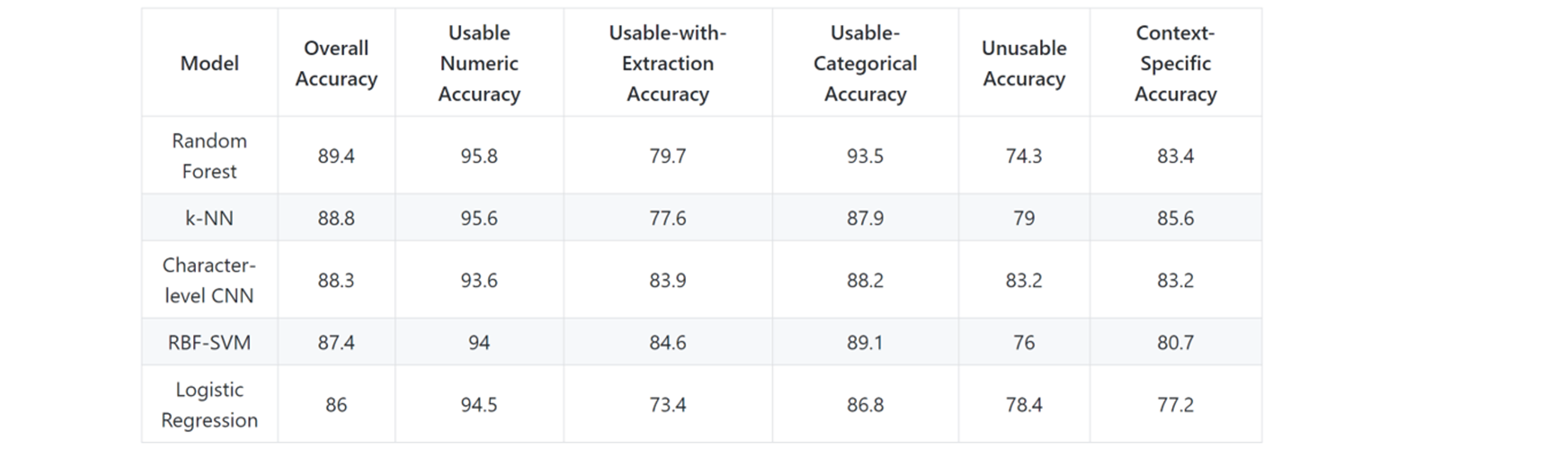
The overall classification accuracy on the complete 5-class vocabulary is given below.
ML Data Prep Zoo Announcement
We announce a live public repository for common ML data prep tasks here. We plan to release labeled datasets, ML models and Python libraries for the defined data prep tasks. For Task 0, we have already released raw dataset, labeled dataset, pre-trained models and python library for using the model. The repository also includes a leaderboard for public competition on the hosted dataset. We invite practitioners and researchers to use our datasets to create better featurization, models and report their results to the leaderboard. Moreover, we invite contributions to define new tasks along with their own labeled data and models.
Conclusions
We envision a community-driven effort for semi-automating data prep based on the philosophy: Formalize data prep tasks as applied ML tasks and create benchmark labeled datasets. Our case study on the ML feature type inference task shows that our applied ML approach can lead to substantial boost in accuracy against existing approaches. We invite you to read our full technical report. Feel free to reach us for any questions, suggestions, and/or comments.