Query Optimization Meets CNNs
This post is regarding my recent paper titled Incremental and Approximate Inference for Faster Occlusion-based Deep CNN Explanations which got accepted to SIGMOD 2019 Conference. This is my first tier one accepted paper and I am humble to say that it was selected as one of the honorable mentions for best paper award. The paper focuses on applying database inspired optimizations to accelerate a class of deep convolutional neural network (CNN) workload called occlusion experiments. The award committee described the topic as “hot and of growing importance”, and were impressed by the novelty and innovation on transfer of database knowledge to — seemingly — unrelated domains.
As CNNs are getting widespread adoption, one of the main concerns is the explainability of CNN predictions. This is a very important aspect in critical applications such as in healthcare. How to explain CNN predictions is still an active research field. However, in the practical literature we found occlusion-based explanation (OBE) is a widely used approach especially by domain experts.
OBE is a very simple and intuitive process. You select a black or gray patch and cover the input image and see what happens to the predicted probability. Then you systematically move this patch over the image and at each position observe what happens to the predicted probability. From this you can generate a heatmap for the variation in the predicted probability and thereby get an intuition on the CNN prediction process. Animation below depicts how OBE can be used to explain why a CNN is predicting “has pneumonia” for a chest X-Ray image (source: http://blog.qure.ai).
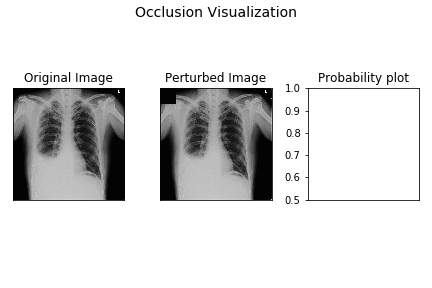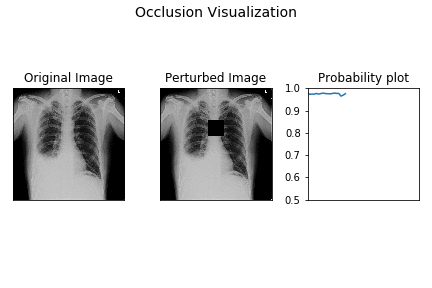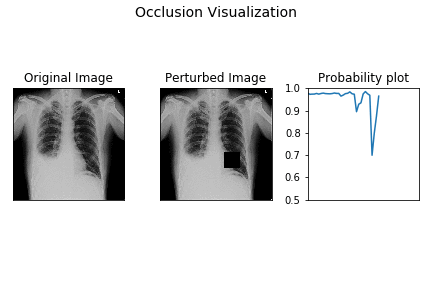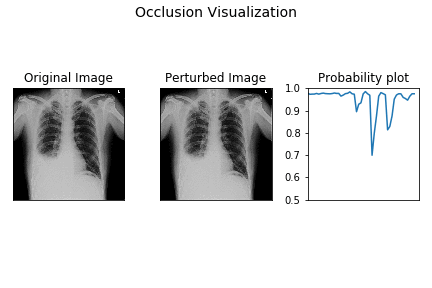
However, OBE is highly time consuming. CNN inference is already compute intensive and OBE just amplifies it by creating possibly hundreds or thousands of occluded instances of the original image. Thus OBE can take from few seconds on GPUs to up to few minutes on CPU only systems. This can hinder the adoption of this technique in interactive and mobile use cases.
Summary of our contributions
In this work we propose Krypton, a system to accelerate OBE by casting it as a query optimization problem. In summary, given an occluded instance of the original image we treat each layer in the CNN as a query. The existence of multiple such occluded images create multiple but related queries. This is essentially an instance of the multi-query optimization (MQO) problem. We first materialize all the intermediate outputs of the CNN corresponding to the original image. To exploit the redundant computations in the queries we have implemented an algebraic framework which performs incremental CNN inference – inspired by the incremental view-maintenance technique in RDBMS – using the materialized CNN layer outputs. A high-level diagram of our incremental CNN inference approach is shown below.
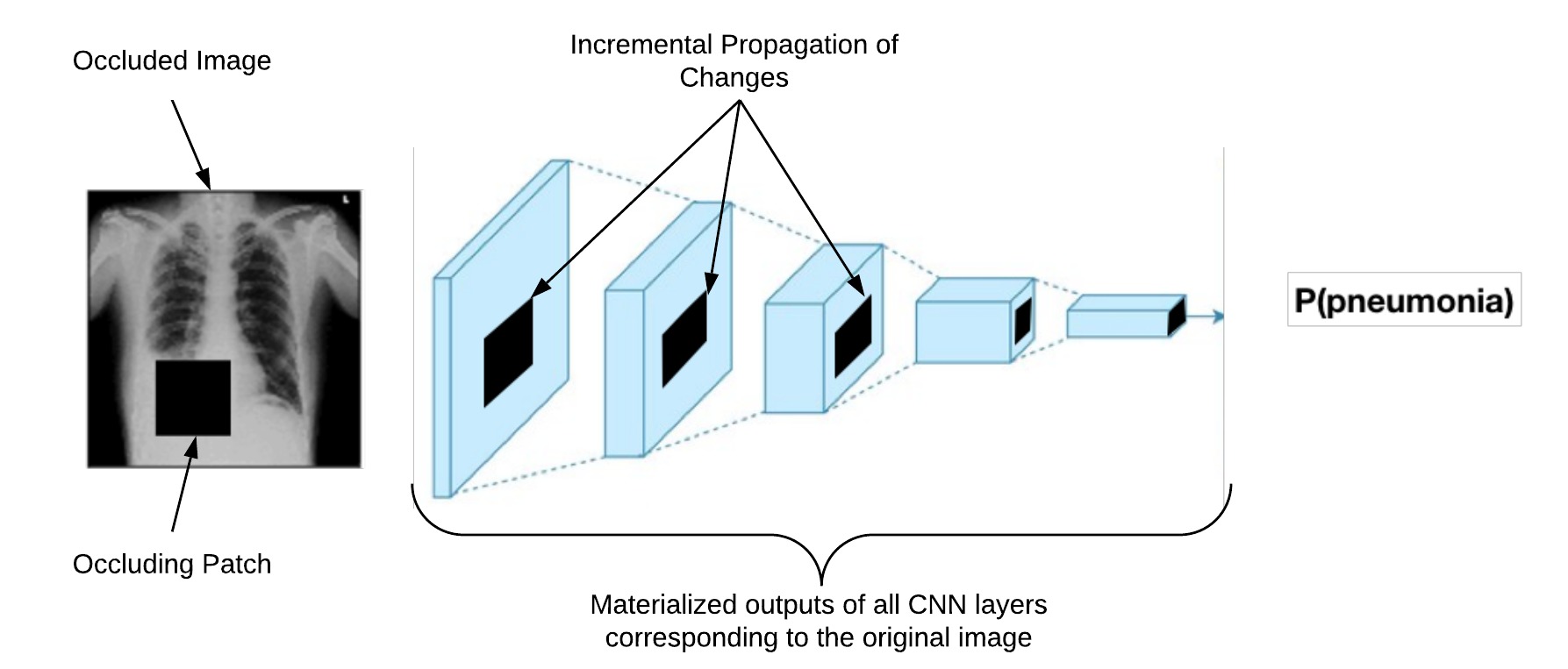
In addition to the incremental CNN inference, which is exact, we also perform two approximate inference optimizations. These approximate inference optimizations trade-off the quality of the OBE generated heatmap with the execution time of the workload. The first approximate inference optimization is called “projective field thresholding” which builds on top of our incremental inference framework. The projective field of a change in the input image (such as an occlusion) is the set of all units which gets affected by it. Projective field essentially captures the change propagation path in a CNN (the black shaded region in the above diagram). Due to the overlapping nature of convolution operation the amount of affected units at each layer keeps on getting increased at every layer. In this work what we showed was that we can truncate the growth of this projective field up to a certain level and still ensure significant quality of the generated heatmap. The truncation of the projective field avoids more redundant computations and thus improves the runtime.
Our second approximate inference optimization is called “adaptive drill-down” approach. This optimization is motivated by the observation that in many OBE applications the sensitive region or the regions of interest are localized and only captures a fraction of the image. Thus inspecting the whole image at a higher occluding granularity is wasteful. What we suggest is a two stage approach. In the first stage we occlude the image at a higher resolution which produces a coarse grained OBE heatmap. In the second stage we drill-down into a fraction (configurable) of the stage 1 heatmap at a higher occluding resolution. Finally we combine the output from both stages to produce the final output. We found that with this two stage approach we can essentially generate the same quality heatmap as if were generating the OBE heatmap at a higher resolution for the entire image but at a lower computational cost.
We have also developed intuitive and easy to use approaches for tuning the approximate inference configuration parameters which includes the truncation threshold for projective field thresholding and drill down fraction for adaptive drill-down method. More details on these techniques can can found in our paper.
Concluding remarks
Krypton belongs to a broader group of our projects which try to improve machine learning workloads by performing data management inspired techniques. In particular the techniques in Krypton are inspired by the long line of work on multi-query optimization, incremental view maintenance, and approximate query processing techniques in the data management literature. By reducing the runtime of OBE, Krypton makes OBE more amenable for the interactive and/or mobile diagnosis of CNN predictions.
A demonstration of Krypton can be found below:
Finally, we invite you to read our research paper. Questions, suggestions, and comments are more than welcome!