ADALab at VLDB and KDD 2021
VLDB is one of the premier conferences for research on databases and data systems;
KDD, on data mining.
Much to some attendees’ chagrin, they happen to fall on the same week in 2021.
ADALab members and alumni are attending both with a packed program of talks, panels, and a demo.
This post is a one-stop shop for what we are up to at VLDB and KDD this year.
- 2 full research papers at VLDB: Both from Project Cerebro.
- 1 research demonstration at VLDB: Also from Project Cerebro.
- 1 industry track paper at VLDB: From Project Morpheus.
- 1 panel discussion and 1 round table chat at VLDB.
- Organizing an invited talk series on data science at VLDB.
- 2 research talks at KDD.
This post presents vignettes on all of our presentations. If you want to start with a
birds-eye view of how all this fits into ADALab’s larger research focus of data
management and systems for ML/AI, please see the overview of our lab’s work in
this prior post
on our presence at SIGMOD 2019.
NB: All talk videos will be made public by both conferences after their events.
If you would like the video links, feel free to check this page again next week for an update.
Edit on Aug 24: I have added links to the available videos.
Overview of ADALab Papers at VLDB 2021
Cerebro meets Data Systems. Paper. Project webpage. Blog post. Talk video.
We had recently published a bunch about our Cerebro system and a new parallel execution technique
for stochastic gradient descent we call Model Hopper Parallelism (MOP),
including on this blog.
Our friends over at Apache MADlib / Pivotal (now part of VMware) got interested in adopting MOP for enabling distributed deep learning
model building over Greenplum. Yuhao interned with them and helped ship MOP as part of MADlib;
see their blog post.
We then decided to study the larger tradeoff space of how best to bring MOP to parallel data systems.
This research paper lays out that comparative study, both analytically and empirically.
We elucidate new Pareto tradeoffs in execution approaches spanning MADlib’s regular fully
in-RDBMS approach, a new partially in-RDBMS approach,
a new in-DB but not in-RDBMS approach, and export-to-Spark.
I think this paper is a must read for all DBMS and cloud vendors interested in offering
more native support for DL tools such as TensorFlow or PyTorch to their DB customers.
I’d suggest starting with Yuhao’s blog post first.
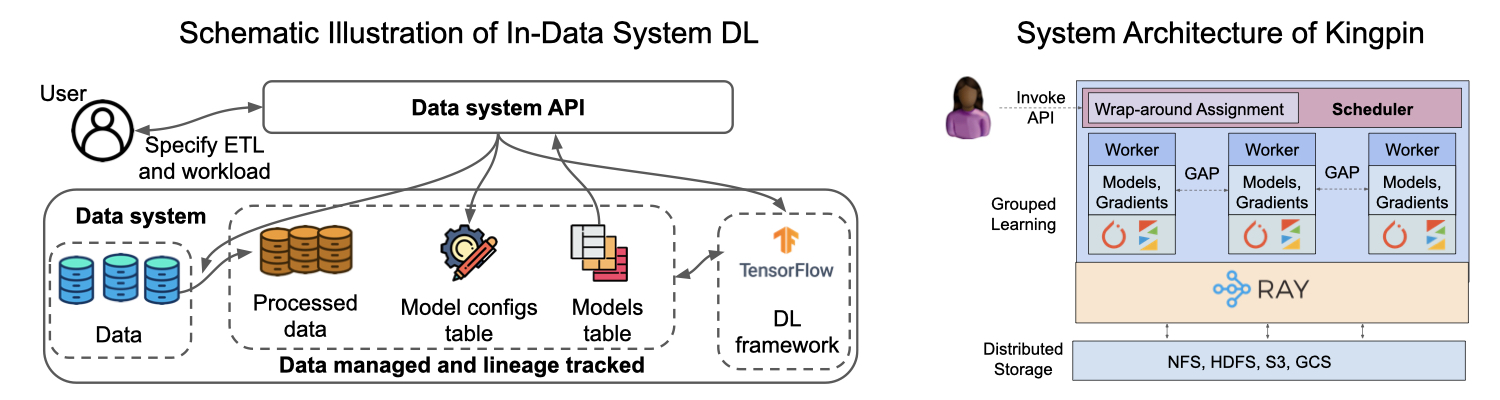
Kingpin (part of Cerebro). Paper. Project webpage. Talk video.
In the Cerebro project we are exploring a larger space of hybrid parallelism
techniques to improve resource efficiency for ML/DL workloads.
In this research paper, Side identifies and studies in depth a new tradeoff space
underappreciated so far in ML systems: building separate models for data sub-groups.
This practice, which we call learning over groups is now common in many enterprise
and Web applications to improve accuracy, privacy, and/or resource management for serving.
However, prior art leaves a lot on the table by using narrow one-dimensional
approaches such as task parallelism or data parallelism alone.
We devise a novel paradigm we call grouped learning, including a new parallel
execution technique for gradient descent we call Gradient Accumulation Parallelism (GAP),
to bridge this gap. Our optimization ideas are applicable to many kinds of ML access
patterns: GLMs, DL, and GBDT. We prototyped Kingpin on PyTorch, LightGBM, and the massively
task-parallel runtime Ray. These ideas will eventually be folded into the larger Cerebro platform.
This paper should be a fun read for those interested in new scalable systems and query
optimization techniques for ML/DL, as well as ML users interested in more efficient
learning over groups.
Cerebro Demo. Paper. Project webpage. Demo video.
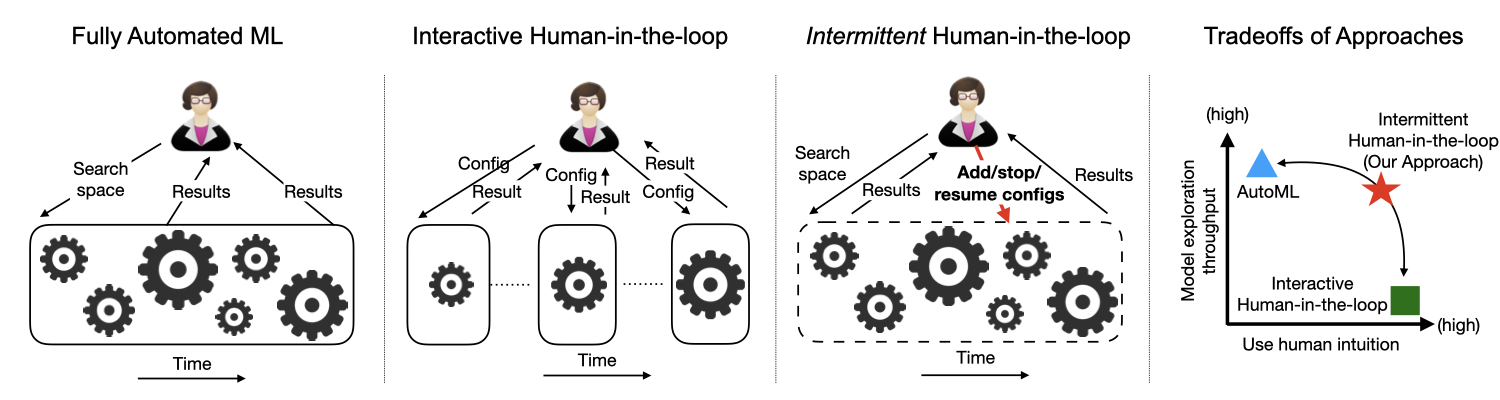
In this demonstration, Liangde and Supun present our new interface for Cerebro that
breaks a pervasive (false) dichotomy in DL interfaces: interactive human-in-the-loop
specification vs offline one-shot Automed ML (AutoML) heuristics. Our experiences
with large-scale DL model building for domain science applications shows that an
intermittent specification interface that bridges this gap between fully manual
and fully automated is ideal for DL due to the long runtimes of DL training.
Users can spawn a large set of DL configurations in one go, observe and kill unproductive
configurations over time, clone/modify productive configurations to explore more,
and do much more, all from a unified dashboard GUI.
We leverage TensorBoard for visualization of all model metrics.
This should be a fun demo to check out for all users of DL, as well as people interested
in studying human-in-the-loop ML tools.
Do check out this short demo overview video.
Trinity (part of Morpheus). Paper. Project webpage. Talk video.
We have published a bunch before on factorized learning, a paradigm I had introduced
in my PhD days to push ML computations down through joins of tables to speed up ML
over multi-table datasets. We had since generalized that idea to all kinds of ML programs
expressible in the formal language of linear algebra (matrix arithmetic).
In this industry track paper, David and Shaoqing take that to the next level by showing how to
generalize the factorized linear algebra framework itself to multiple programming languages
with a single unified implementation leveraging Oracle’s GraalVM polyglot compiler and runtime.
This is a great case study of bringing together cutting-edge DB+ML research and PL/compilers
research to help the emerging polyglot industrial data science landscape.
This paper should be a fun read for both DB/ML systems folks and PL/compilers folks,
as well as for people building new tools for end-to-end data science workloads.
Our Other Activities at VLDB 2021
I myself am also participating in and/or co-organizing three other activities at VLDB:
Panel Discussion on The Future of Data(base) Education. Webpage
We are going to debate whether DB education has become outdated and if so, how to evolve
in this new era of Data Science. This topic is near and dear to my heart as an educator.
I have been creating new courses at UC San Diego, including
undergraduate DB Systems Implementation for CSE
(a course on RDBMS internals),
undergraduate Systems for Scalable Analytics for HDSI
(a first-of-its-kind course in the world aimed at Data Science juniors),
and graduate Data Systems for ML for CSE
(one of the first courses in the world on the cutting edge of ML systems).
I also co-authored the first research-oriented textbook on ML systems,
co-defined CSE’s MS depth in Data Science, and co-defined HDSI’s data systems
course series for both BS and graduate levels. I am helping create UCSD’s first
Online Masters degree in Data Science, run jointly by CSE and HDSI.
I look forward to sparring with the other panelists and host on the pressing questions
and lessons for DB education going forward!
Edit: Video of panel discussion.
Round table on Systems for ML.
Along with Chris Jermaine, I am co-hosting this round table for this sub-area of
Systems for ML for VLDB attendees. We have confirmed a set of awesome
panelists with expertise in this area to stir discussion: Carlo Curino, Ce Zhang, Jun Yang,
Manasi Vartak, Matei Zaharia, Matthias Boehm, Paroma Varma, and Sebastian Schelter.
Looking forward to it!
Invited SDS Talk Series.
This was the inaugural year of VLDB’s new Research Track category called Scalable Data Science (SDS).
I helped define and run it as an Associate Editor; see this SIGMOD Blog post.
It seems to have been a hit with the VLDB community: a slew of exciting and eclectic SDS papers are
appearing at VLDB 2021 from many top companies and universities around the world.
To celeberate the launch of SDS, the SDS AEs (Alon, Nesime, and I) invited 6 stellar speakers
from both academia and industry to share about their boundary-pushing work in the SDS arena:
Joaquin Vanschoren, Anja Feldmann, Danai Koutra, Matei Zaharia, Manasi Vartak, and Nigam Shah.
Please see this webpage for their talk details
Overview of ADALab Talks at KDD 2021
Finally, I am also attending KDD to give two research talks:
Invited talk at the KDD Applied Data Science (ADS) talk series. Program webpage.
The ADS track of KDD was one of the inspirations for VLDB’s SDS, although the rationales and
criteria are a bit different.
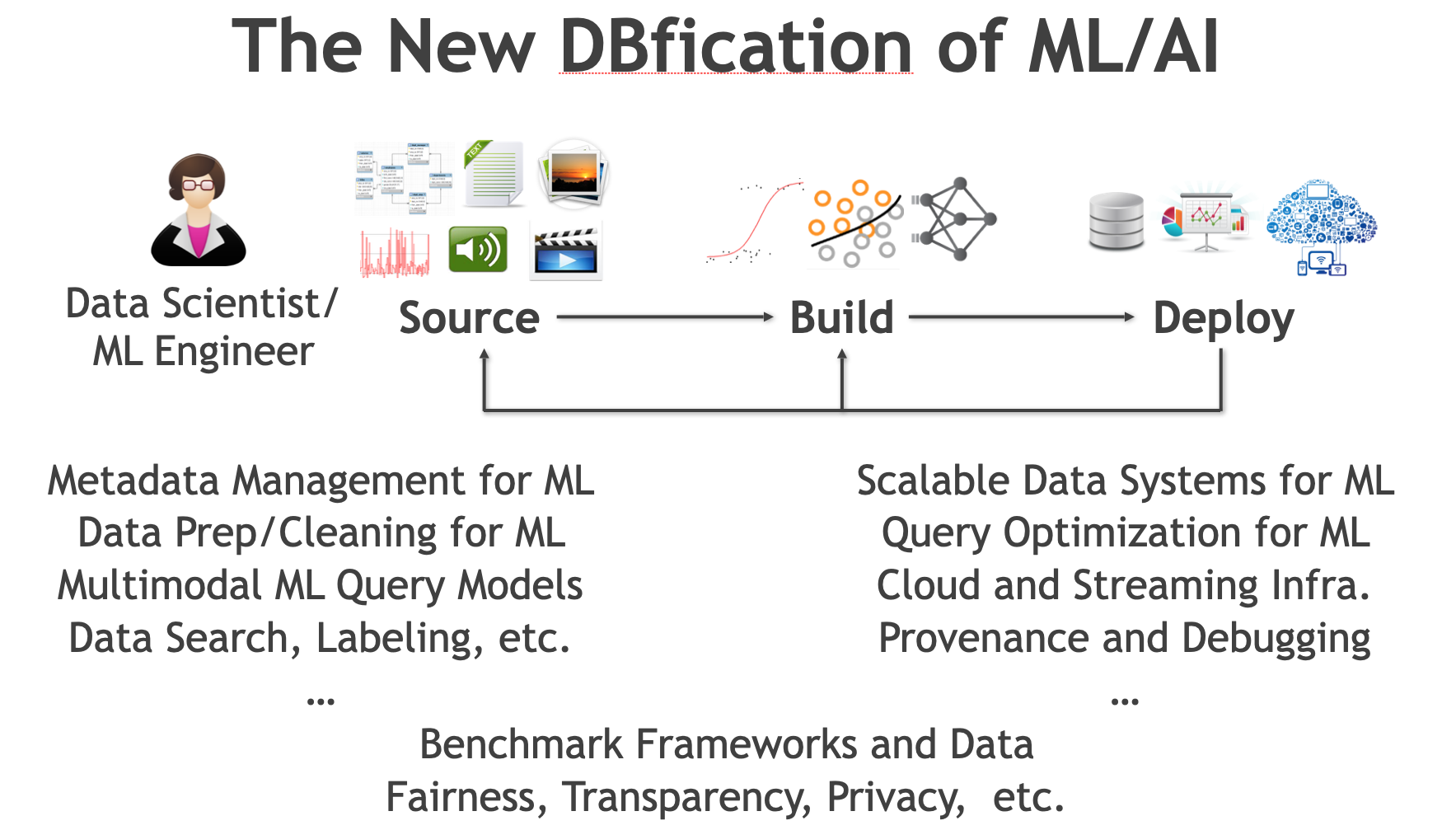
I will be speaking about what I see as the new “DBfication” of ML/AI and how the data
mining community can join forces with the DB and other research communities to help democratize ML/AI.
Talk at Deep Learning Day. Talk Abstract. Program webpage.
Along with Supun and Yuhao, I had sent in a talk proposal to this cool event
that aims to reflect on various issues in the state of DL practice and research.
I will be speaking about a set of major issues I see in DL practice centered on
issues of model selection and system scalability. Or as I phrase it more colorfully,
I will bust some common “damaging delusions” of DL practice. I will also cover how
DL users and system developers can avoid those delusions by drawing upon our experiences
in Project Cerebro.
Edit: Talk video.
Overall, we have a large mix of presentations by ADALab members at VLDB and KDD in just 3 days.
We look forward to learning more from the audience questions and feedback on our work.
I also hope our work and experiences inspire more researchers and students to work in this
exciting direction of data management/systems for ML/AI–or as I like to call it,
the new DBfication of ML/AI. :)
ACKs: A huge thank you to all of our research collaborators, supporters, and sponsors!
