Just Speak SQL
This post is regarding our project SpeakQL. SpeakQL will appear at SIGMOD 2020 in the research track. The paper titled SpeakQL: Towards Speech-driven Multimodal Querying of Structured Data is available here. It is co-authored with Side Li, Kevin Yang, Arun Kumar, and Lawrence Saul.
Introduction
We witness a widespread adoption of speech based inputs today as speech recognition engines are becoming really powerful. People are speaking and interacting with their smartphones, tablets and even conversational assistants such as Amazon’s Alexa, Microsoft’s Cortana, and Apple’s Siri.

For the database world, “typed” SQL is the standard language for communicating with the relational data. Users in several domains such as enterprise, healthcare, and web are familiar with SQL and use it daily. Many prior works look at creating natural language interfaces (NLIs) to allow users to query their data in natural language. However, they have completely ignored the SQL knowledge of many users. As shown in the image below, there exist users along an entire spectrum of expertise. Besides expert SQL wizards and lay users, there are many people such as analysts, nurse informaticists, and managers who are comfortable with basic SQL and perform mostly read-only queries of their data.
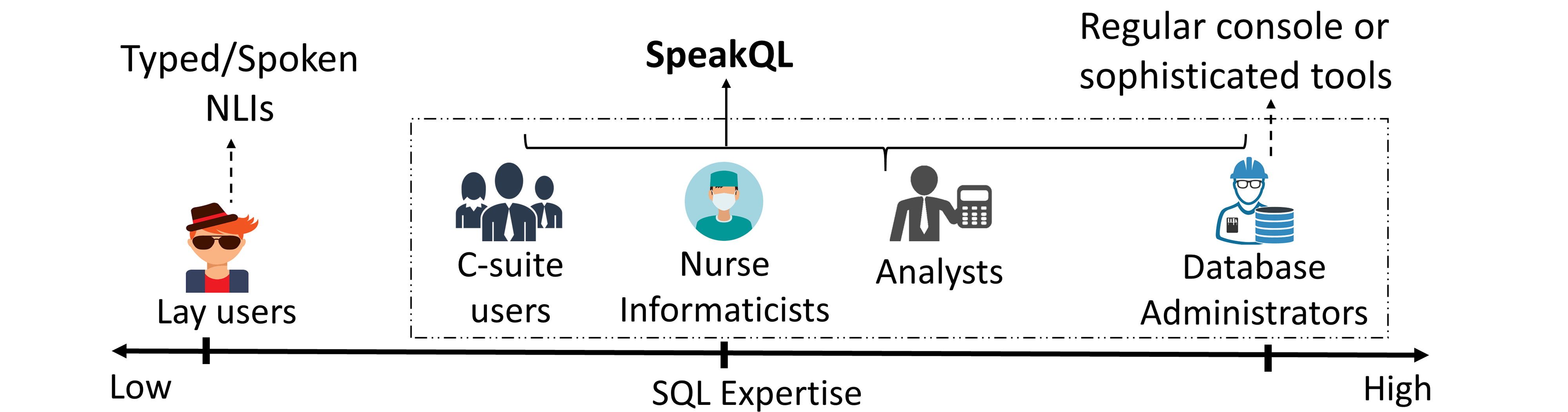
We spoke with many users in industry and found that they compose ad hoc queries over arbitrary tables and desire unambiguous responses to their queries. In addition, they often desire anytime and anywhere access to their data, say via mobile platforms such as smartphones and tablets. However, typing SQL is really painful in such environments. Having a speech-driven querying system on their smartphones/tablets that exploits both speech and touch capabilities will help them specify queries faster. Furthermore, SQL offers many advantages that practitioners find useful. For instance, SQL offers a lack of ambiguity due to its unambiguous context-free grammar (CFG) and a high-level of query sophistication. Most importantly, with SQL, the users know that the results will match their posed queries. In contrast, natural language does not offer any such guarantees.
In this work, as the very first step, we build a spoken querying system for a subset of SQL. We call this SpeakQL, which is an end-to-end speech-driven system that allows the user to dictate an SQL query, perform interactive query correction using speech/touch, and finally, the user can see the results on the screen.
Technical Challenges
In contrast to English speech, the SQL speech offers several interesting technical challenges such as following.
-
SQL contains only 3 kinds of tokens: Keywords, Special Characters, and Literals. SQL Keywords (such as SELECT, FROM, etc.) and Special Characters (such as * , =, etc.) are from a finite set. On the other hand, Literal can be a table name, an attribute name or an attribute value. Table names and attribute names have a finite vocabulary but the attribute value can be any value from the database or any generic value. Thus, SQL offers infinite types of literal instances such as CUSTID_1729A. Since such tokens are not present in any automatic speech recognition (ASR) engine’s vocabulary, they are typically split into a set of multiple tokens or not recognized at all. Such out-of-vocabulary tokens are more likely in SQL than natural English. We call this the unbounded vocabulary problem and it presents us with a major technical challenge.
-
Even for in-vocabulary tokens, ASR is bound to make mistakes due to homophones. SQL Keywords or Special Characters are often converted to Literals or vice versa. For instance, a Keyword “sum” is recognized as Literal “some”. More types of errors can be found in the table below.
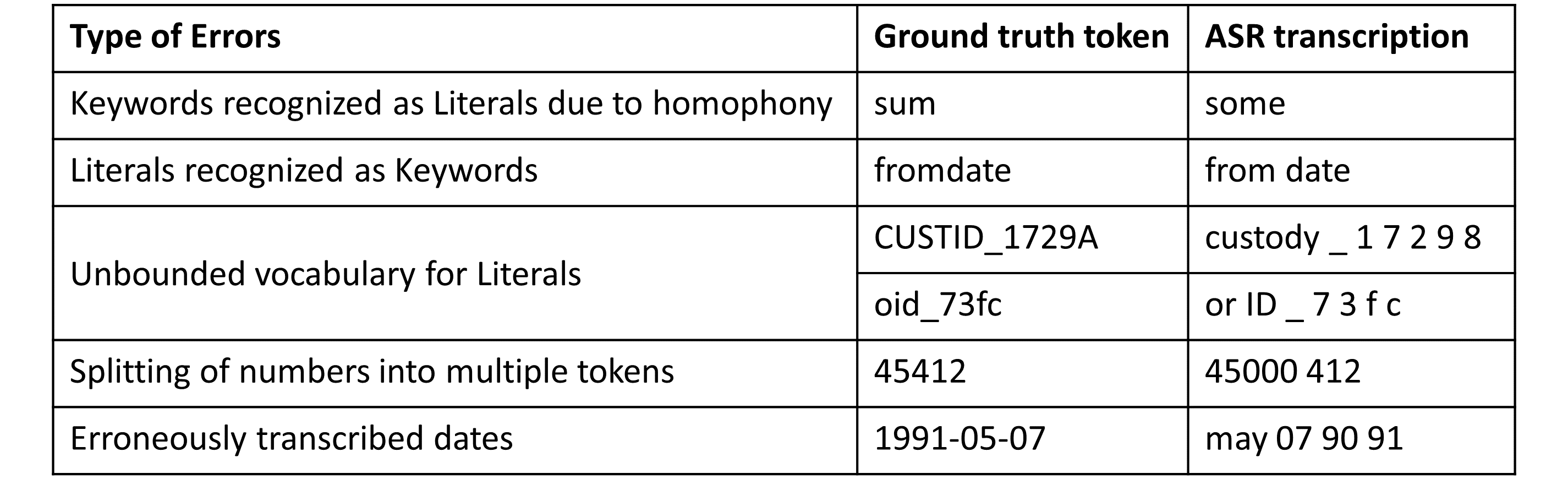 We tried out with many existing ASR tools such as Google’s Cloud Speech API, Amazon’s Transcribe, Azure’s Custome Speech Service, Baidu’s DeepSpeech 2, and Facebook’s wav2letter. We found that these tools (except Azure’s Custom Speech) does not capture the vocabulary of the underlying application and hence their accuracy for non-standard English words is extremely low.
We tried out with many existing ASR tools such as Google’s Cloud Speech API, Amazon’s Transcribe, Azure’s Custome Speech Service, Baidu’s DeepSpeech 2, and Facebook’s wav2letter. We found that these tools (except Azure’s Custom Speech) does not capture the vocabulary of the underlying application and hence their accuracy for non-standard English words is extremely low. -
Achieving real-time latency is another major concern for us. For instance, Amazon Transcribe took nearly 8s to transcribe 20-sec audio. This is completely unacceptable for an interactive interface.
Our Contributions
To tackle the above challenges, we present the following 4-component architecture.
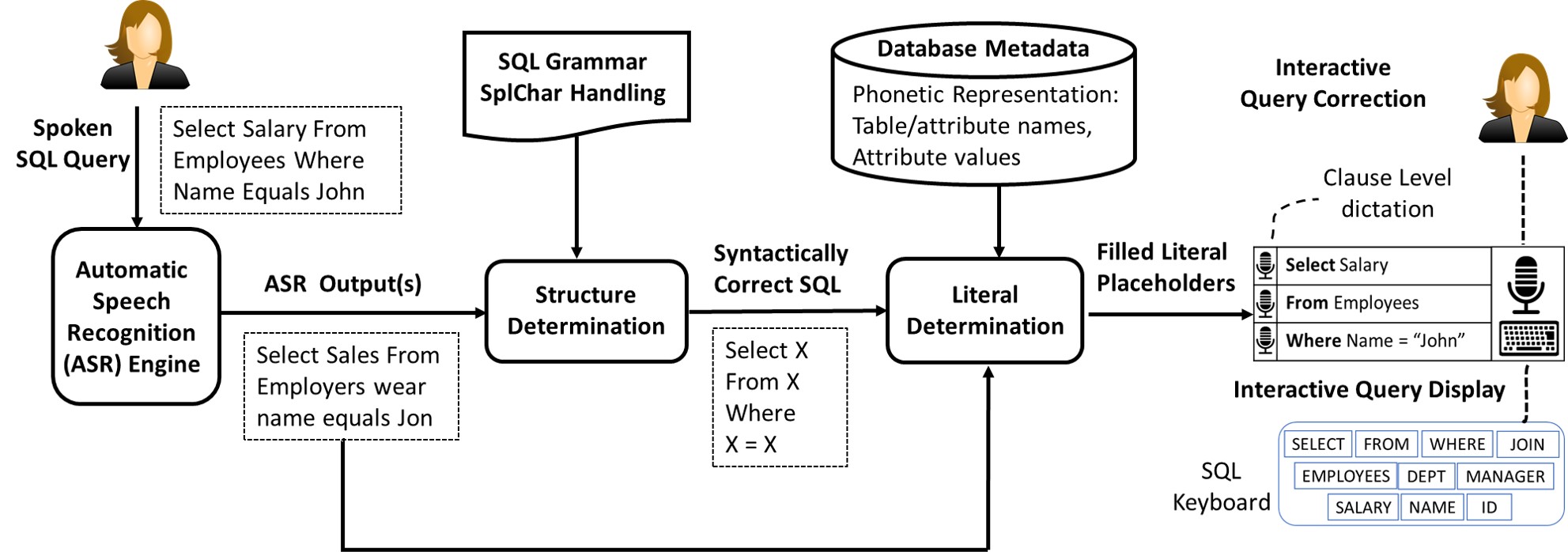
Our most important design decision is to decompose the problem of correcting ASR transcription errors into two tasks, structure determination and literal determination. This architectural decoupling lets us effectively tackle the unbounded vocabulary problem. I discuss the high-level intuitions of each of the components below.
ASR engine. This component processes the recorded spoken SQL query to obtain a transcription output. We use Azure’s Custom Speech Service for our ASR.
Structure determination. Processes the ASR output to obtain a syntactically correct SQL statement with placeholder variables for Literals, while Keywords and Special Characters are fixed. It leverages the underlying rich structure of SQL using its CFG to generate many possible SQL structures. A SQL structure is a syntactically correct SQL string obtained from our SQL grammar by applying the production rules recursively. These structures are indexed using the trie data structure. We propose a similarity search algorithm (dynamic programming on tries) that exploits SQL-specific properties to identify the closest matching structure.
Literal determination. We create a literal voting algorithm to identify the literals for the placeholder variables. Our algorithm is based on our observations about how ASR fails to transcribe literals correctly.
-
ASR messes up when transcribing a number spoken with pauses. “forty-five thousand three hundred ten” is transcribed as “45000 310”. This makes us realize that the literal determination component should be made aware of the splitting of tokens into sub-tokens so that it can decide when and how to merge these sub-tokens.
-
Homophony is a big challenge for an ASR to overcome. Hence, we consider a similarity search on a pre-computed phonetic representation of the existing Literals in the database. This helps us disambiguate between the words sounding similar.
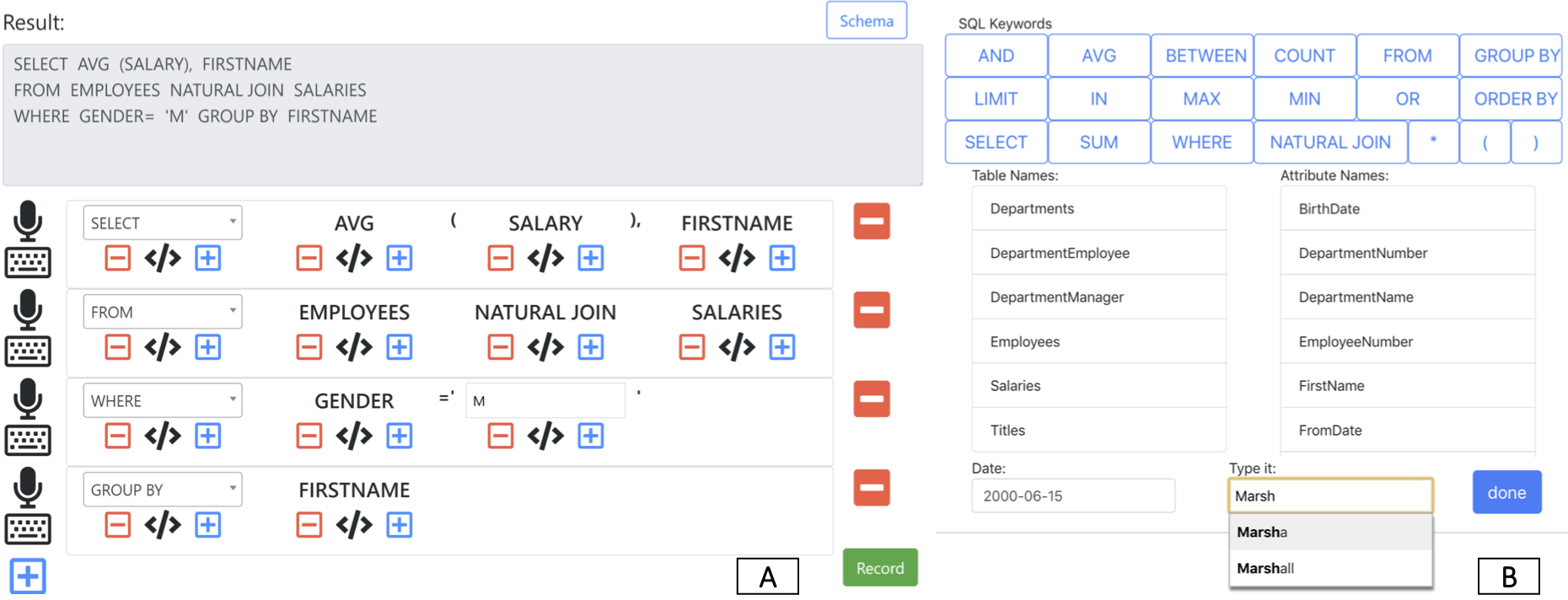
Interactive Interface. provides a touch-based interface for users to dictate SQL queries and interactively correct them. The motivation behind it is simple. We want the tool to 1. be intuitive enough to perform/adjust dictation and 2. accelerate the process of correcting queries. In terms of dictation support, users can click the large record button to start/stop dictations. If needed, users can also dictate the queries on the clause level. To speed up the interactive correction, we devise a novel SQL keyboard that’s suitable for a quick in-place editing of stray incorrect tokens, present anywhere in the SQL query string. The keyboard consists of frequently used SQL keywords, attribute names as well as Date selection. If our system fails to identify a phonetically ambiguous word, users can still type it up with the help of auto-completion.
Evaluation through User Study
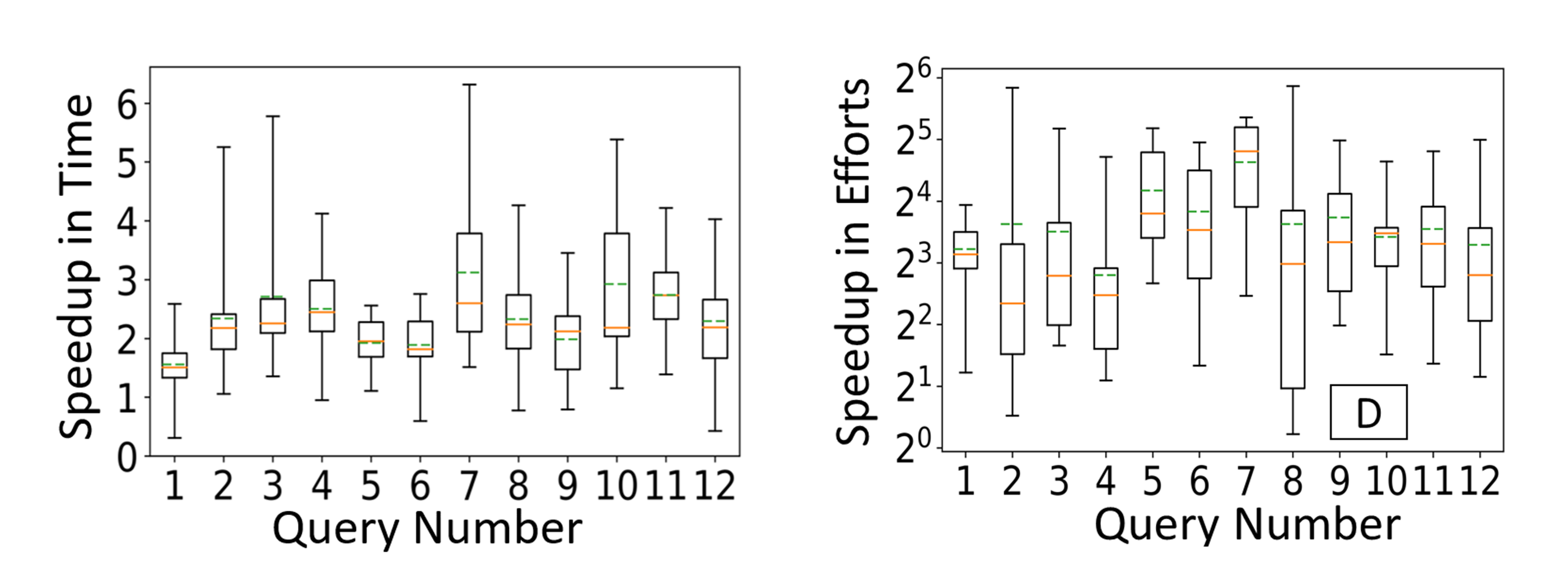
We conduct a user study by recruiting 15 participants familiar with SQL. We include Select-Project-Join-Aggregate queries. Each participant composed 12 queries on a tablet device and performed two task: (1) In the first task, they had access to SpeakQL Interface which allowed them to dictate SQL queries perform interactive correction with touch/speech and (2) In the second task, they typed the query from scratch with no access to our interface. The speedup in time and user effort across 12 queries is provided below. We notice that SpeakQL leads to a significantly higher speedup in time to completion, an average of 2.7x and up to 6.7x than raw typing SQL queries. Moreover, with SpeakQL’s multimodal interface, the user touch effort to specify and/or correct the query goes down by a factor of average 10x and up to 60x compared to raw typing.
Concluding Remarks
Overall, we found that SpeakQL’s unique multimodal design allows users to compose queries significantly faster and reduces their touch effort in specifying or correcting the query. Our techniques are inspired from disparate literatures such as database systems, natural language processing, information retrieval, and human-computer interaction. We build an end-to-end system adapting these techniques to the context of spoken SQL based on the syntactic and semantic properties of SQL queries. This project is our first step in making speech-driven querying of structured data effective and efficient.
A short video describing our system can be found below.
A demonstration video of SpeakQL (created for the user study) can be found below.
We invite you to read our full technical report. Feel free to reach us for any questions, suggestions, and/or comments.