Generating Predictions from Pre-Trained Models
You can use the released pre-trained models to generate predictions using your own data. To do so invoke the make_predictions.py as follows:
python make_predictions.py --pre-processed-dir <pre_processed_data_dir>
Complete usage details of this script are as follows:
usage: make_predictions.py [-h] --pre-processed-dir PRE_PROCESSED_DIR
[--model {CHAP_A,CHAP_B,CHAP_C,CHAP,CHAP_ALL_ADULTS,CHAP_CHILDREN}]
[--predictions-dir PREDICTIONS_DIR]
[--no-segment] [--output-label]
[--silent] [--padding {drop,zero,wrap}]
[--amp-factor AMP_FACTOR]
Argument parser for generating model predictions.
required arguments:
--pre-processed-dir PRE_PROCESSED_DIR
Pre-processed data directory
optional arguments:
-h, --help show this help message and exit
--model {CHAP_A,CHAP_B,CHAP_C,CHAP,CHAP_ALL_ADULTS,CHAP_CHILDREN}
Pre-trained prediction model name (default:
CHAP_ALL_ADULTS)
--predictions-dir PREDICTIONS_DIR
Predictions output directory (default: ./predictions)
--no-segment Do not output segment number
--output-label Whether to output the actual label
--silent Whether to hide info messages
--padding {drop,zero,wrap}
Padding scheme for the last part of data that does not
fill a whole lstm window (default: drop)
--amp-factor AMP_FACTOR
Factor to increase the number of neurons in the CNN layers (default: 2)
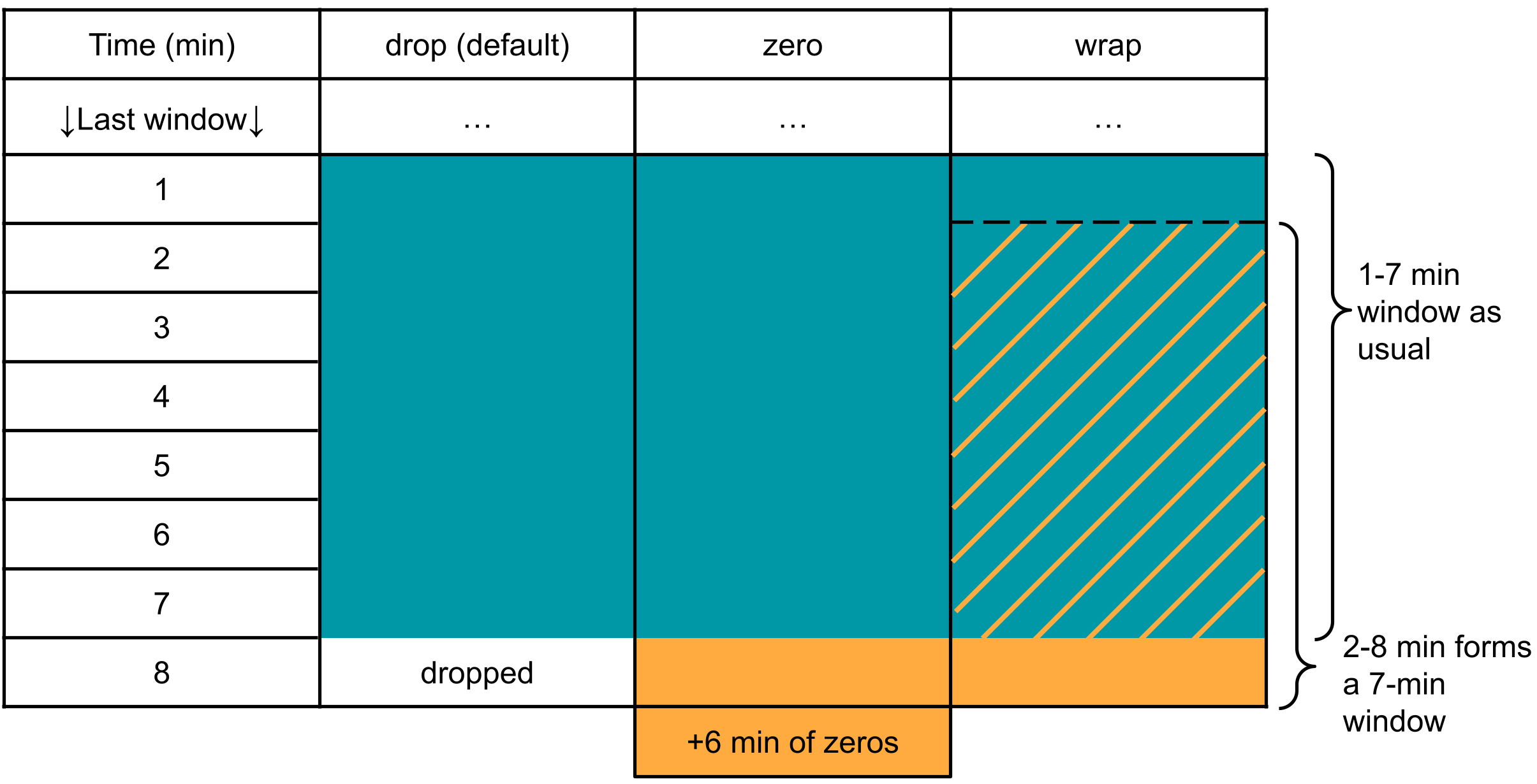
The three schemes of padding/imputation:
Imagine at the end of our file, we have 8 minutes of data, which can form one 7-min window but the last minute becomes dangling since our window size is 7 minutes. Our code will default to dropping the last 1 minute and will not make predictions from it. We also provide two methods to utilize it by imputation/padding potentially. Below is a detailed description of each technique.
- drop (default). The default behavior, drop the last a few minutes (1 minute in this case).
- zero. We pad extra minutes with zeros (6 minutes in this case), which are concatenated with the dangling minutes (the last 1 minute of the data in this case) to form a complete 7-min window. This window is then used to generate predictions for the last dangling minutes.
- wrap. This method traces back and wraps the past few minutes to form a 7-min window. In this case, min 2-8 is used to generate predictions for min 8. However, predictions for min 2-7 are still generated based on data from the preceding window (min 1-7).
All of the above methods are situational, and statistically speaking, prediction accuracy on the last few minutes cannot be guaranteed. Hence the last few minutes should be treated differently with caution at user’s discretion. To learn more about the subtle effect, see our study.
Suppose the above methods do not suit your purpose. In that case, you can implement other imputation strategies as appropriate for your study directly on the input .csv file to make the data length a multiple of the window size (7 min). If you do it this way, ignore the --padding argument.