DBMS Inspired Optimizations for Scalable Deep CNN Feature Transfer
This post is regarding our project Vista. Vista will appear at SIGMOD 2020 in the research track. The paper titled Vista: Optimized System for Scalable Feature Transfer from Deep CNNs at Scale is available here. It is co-authored with my advisor Prof. Arun Kumar.
Observation
Machine learning (ML) is revolutionizing many fields. Inspired by the major successes at big web companies, other enterprises have also started adopting ML-based advanced analytics techniques. Most of these advanced analytics pipelines are primarily powered by tabular/structured data. However, in many of these applications, such as in e-commerce, healthcare, and social media, in addition to the structured data, you also have access to large volumes of image data, which are ignored or underutilized. These images contain important information about their corresponding domains and as a result of not being used in their corresponding analytics pipelines, they have essentially become dark data from an analytics point of view.
Opportunity
Recent advancements in Deep Convolutional Neural Networks (CNNs) have tremendously improved our ability to automatically understand images. And they now provide a unique opportunity to integrate image data with structured data for performing multi-modal analytics using a technique called deep CNN feature transfer, a form of transfer learning in ML.
CNN feature transfer works as follows. Assume you are a data scientist working at an online e-commerce retailer and you need to train a product recommendation model using both structured features and also using image data such as the product images. You take a pre-trained CNN (e.g., VGG16 model trained on popular ImageNet dataset), and feed your image data through the CNN and select the output of one of the internal CNN layers as a representation for your images. You then combine the extracted CNN features with your structured features to come up with a multimodal representation of your data, which you can then use to train ML models on.
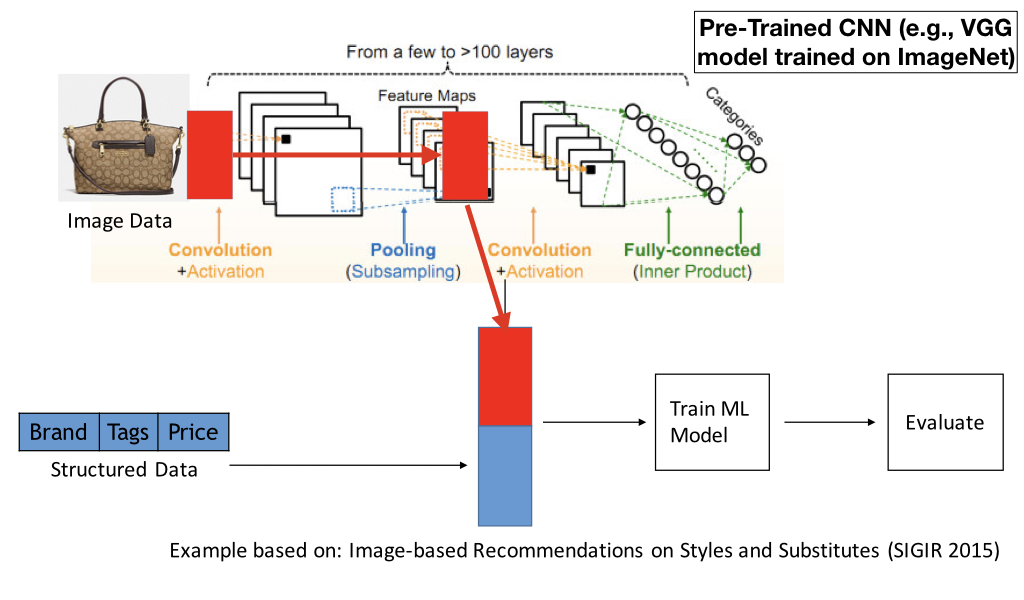
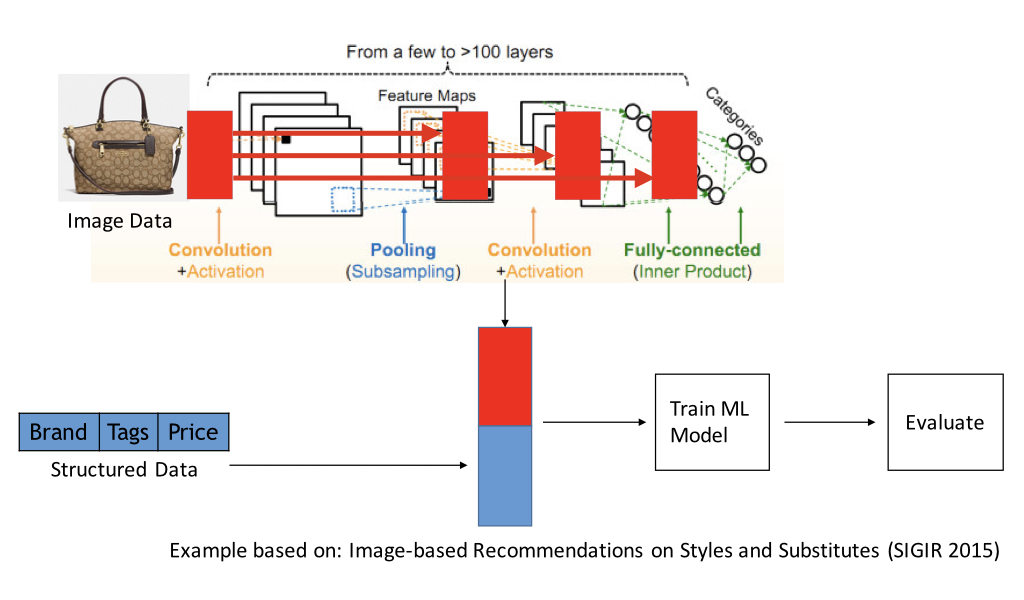
However, a CNN has a lot of layers. Which layer you should use for feature transfer? Unfortunately, you cannot tell beforehand which layer features will work best for your particular task. You have to explore several different layers and pick the layer that works best for your particular task. For example, in the example shown below, the last three layers of the CNN are explored.
Problem
To execute this workload, today there is no single system that you can use. You need to use a deep learning system such as TensorFlow to extract CNN features. These systems are optimized for neural networks and provide seamless hardware acceleration. But such systems do not provide features like performing ETL on structured data, distributed memory/file management, and support for classical ML models such as tree-based ML models, which are provided by parallel dataflow systems such as Apache Spark. Thus users have to use a deep learning system to extract CNN features, export them to files, load the CNN feature files along with structured features into a parallel dataflow system, and then train and evaluate downstream ML models. If you are exploring multiple layers, you will have to repeat this process for all the layers.
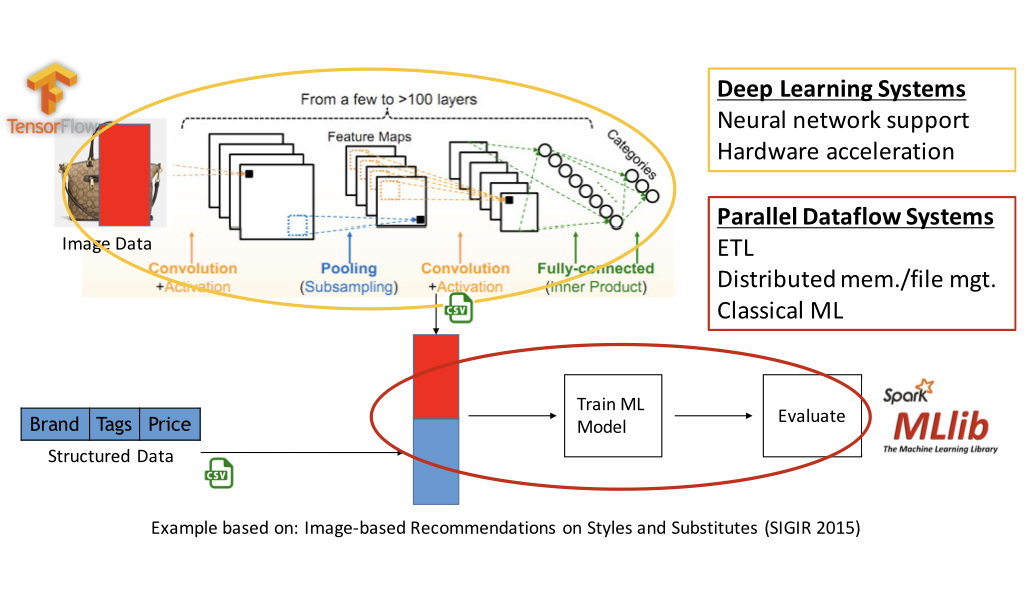
This dichotomy between systems for performing scalable analytics today causes several issues for workloads that want to jointly analyze image and structured data.
-
Usability Issues: Users now have to straddle between two different systems by manually writing and loading feature files which drastically degrades the user experience. Furthermore, executing this workload on deep learning and parallel dataflow systems require a significant amount of low-level configuration knob tuning. ML users can get bogged down by these low-level systems issues whereas they should primarily focus on ML related exploration.
-
Efficiency Issues: Naively exploring multiple layers by exploring one layer at a time can cause significant inefficiencies due to redundant computations. This is because the computations required to extract features for a lower CNN layer are a strict subset of the computations which are required to extract features for a higher layer.
-
Reliability Issues: CNN features can be orders of magnitude larger than their highly compressed input images which are in formats like JPEG. As a result of this size blowup, if the system is not properly configured, it can cause costly disk-spills for storing intermediate data in memory or in certain cases even workload crashes.
Our Contributions
We developed Vista, which is an optimized system for performing the CNN feature transfer workload. It elevates the CNN feature transfer workload to a declarative level so that users can now specify what layers they want to explore instead of specifying how to stage the computations. Vista takes in 4 inputs: 1) structured data, 2) image data, 3) pre-trained CNN and layers interested in exploring, and 4) downstream ML model. Given these inputs, Vista optimizes the CNN feature transfer workload and reliably runs it. It runs on top of existing dataflow systems and deep learning systems to exploit their orthogonal benefits. Vista’s optimizations are inspired by the classical DBMS optimizations.
-
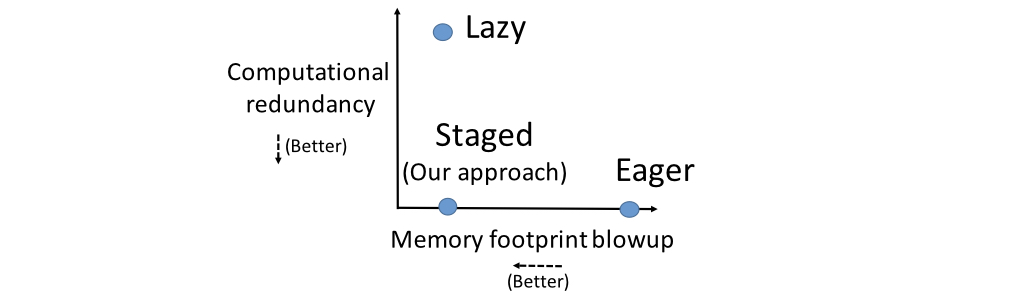
Logical Optimizations: We identify the CNN feature transfer workload as a novel instance of the classical multi-query optimization in databases. If you treat extracting CNN features for a single layer as a query, exploring multiple layers essentially creates a multi-query. The current dominant practice of extracting one layer at a time can be categorized as the lazy materialization approach. The problem with this approach is that it performs a significant amount of redundant computations. Alternatively, you can extract all layers in one go, which can be categorized as the eager materialization approach. This approach does not incur redundant computations but has a high memory footprint and as a result, it can cause costly disk-spills for storing data in memory or in certain cases workload crashes due to exhausting system memory. We propose a new logical execution plan called staged materialization, which exploits the characteristics of CNNs and the CNN feature transfer workload to avoid redundant computations and also to keep the memory footprint to a minimum.
-
Physical Optimizations: Vista optimizes two different physical configuration decisions: 1) join between CNN features and structured features and 2) storage format for storing intermediate data in memory. For the join, the available options are shuffle-based join and broadcast join. These options essentially trade-offs the memory footprint vs network cost. For storing intermediate data the available options are serialized and unserialized. These options essentially trade-offs the memory footprint vs compute cost. Vista automatically sets these configuration values based on the specifics of the given workload and frees the ML user from these low-level systems related issues.
-
System Configuration Optimizations: One of the most important system configuration optimizations that Vista does is the apportioning of memory. When executing a workload that spans across both parallel dataflow and deep learning systems, it creates complex memory requirements. For example, parallel dataflow systems need memory allocated for query execution, user-defined function execution, and storing intermediate data in memory. On the other hand, deep learning systems also need memory for storing CNN models and performing inference on them. If not sufficient memory is allocated for these regions, the workload may crash. If excessive memory is allocated for a region, it may result in wastages and also performance issues due to the lack of memory for other regions. Vista automatically sets these configurations in an optimal manner and frees the ML user so that he/she can now focus on ML-related exploration.
Concluding Remarks
Overall, we found that Vista can improve the efficiency of the CNN feature transfer workload by up to 90% and also avoid unexpected workload crashes due to various memory-related misconfiguration issues. We invite you to read our full technical report. The system code is also publically available. For future work, we plan to support more general forms of transfer learning with deep neural networks, downstream ML tasks, and other forms of unstructured data such as text as well.
A short video explaining the high-level architecture of Vista and the optimization techniques used can be found below.
Feel free to reach us for any questions, suggestions, and/or comments.