Panorama: Video Querying with Unbounded Vocabulary
This is a post about our research project, Panorama. Please check the home page at here. There is a technical report with all the details, and source code/demos on github.
Deep learning has become more popular than ever. It’s also quite convenient to download a cutting-edge deep learning model from GitHub or bitbucket for your application. Face recognition, traffic monitoring, video analytics; most likely, there are already some pre-trained weights. It looks all you have to do is downloading and using them.
Say you got an application for car model recognition, where you want to identify the models and makes of cars in a traffic camera video. You can download a pre-trained model and it can do the work just fine on Ford Mustang and Chevy Camaro:

Or sometimes flaky on a Dodge Challenger:

It believes this Dodge Challenger is in fact a Ford Mustang, 91% sure. Well, this could be a coincidence. After all, you can never trust these machine learning models.
But there’s more to it. In fact, out of the 431 car models it can predict, there wasn’t even Dodge Challenger since it wasn’t in the training dataset. This means it can never figure out the correct answer for any Dodge Challenger.
Just like us, your model needs a vocabulary to name things. And the vocabulary of the training data becomes its fixed vocabulary. Without knowing what the car is, it probably picks the closest pony car rival.
The unbounded vocabulary problem
Unlike static lab environments where the machine learning models were built, the real world is dynamic, and the vocabulary keeps changing. New car models released every fortnight, new animal species discovered from time to time, people come and go, constantly. It’s not easy to keep up and refresh your model often.
To complicate the situation even more. The efforts and expertise required to alter the vocabulary can be tremendous. That state-of-art model for your task can be bespoke and complicated, compositing a dozen sub-models for the final task. To re-train it, you need data science expertise and may need to collect data for each component of it.
Background: Embedding extraction
To mitigate the unbounded vocabulary issue, one can resort to a technique known as embedding extraction or metric learning. Instead of training the deep net for predicting labels, we train the model to yield discriminative features called embeddings. Embeddings of the same entity then gather closer than those of different entities.
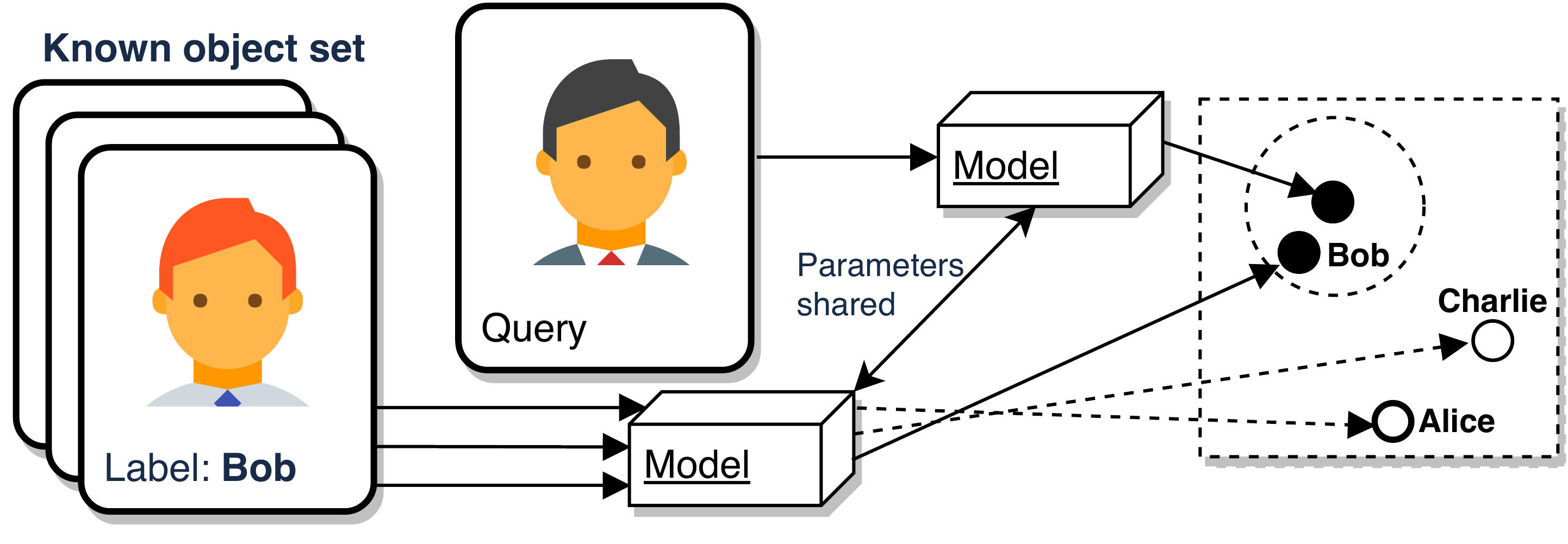
So the object classification becomes a simple nearest neighbor search, and the vocabulary can be expanded on-the-fly.
Deeply supervised cascade processing
Deep nets can have over one hundred layers and very expensive due to the sheer amount of FLOPS required. But do we need all that depth, all that capabilities for more manageable tasks and queries? A solution to it is cascaded processing, where the model is divided into stages and can execute early-exiting or short-circuiting whenever possible.
We developed a novel deeply supervised cascade architecture based on this observation. We also devised an auto-training scheme for setting the hyper-parameters related to short-circuiting criteria. If the practitioner already has a model in deployment, Panorama can also leverage it for week supervision.
Panorama
We then built Panorama to mitigate the unbounded vocabulary problem and designed it to be domain-agnostic and efficient. We rely on the embedding extraction technique solely for fine-grained recognition tasks; hence, we can enable potentially unbounded vocabulary. We built it to be a deeply-supervised cascade so that it can learn to adjust itself when facing different queries.
In our paper, we tested on three domains: faces, bird species, and car models to demonstrate its capability of generalizing beyond supervision received. The user can also plug in an existing model; then, Panorama automatically can utilize the model as a week teacher to train itself. Panorama can substitute or work along with the existing model to provide much higher (2x to 20x) throughput, with some losses on the accuracy (marginally to 20%).
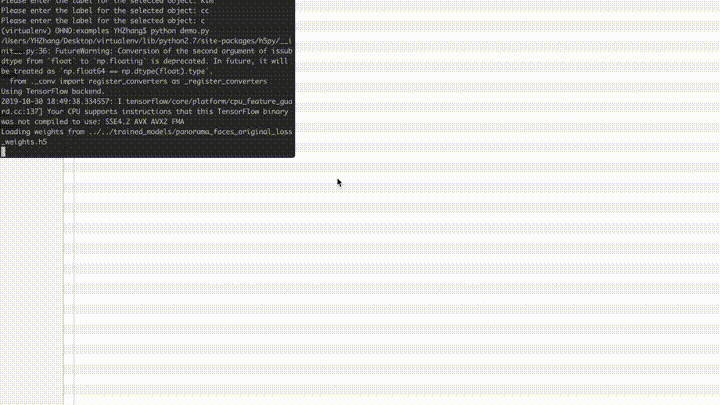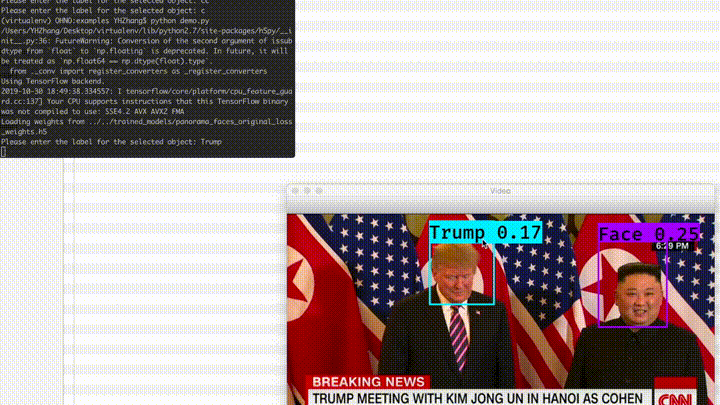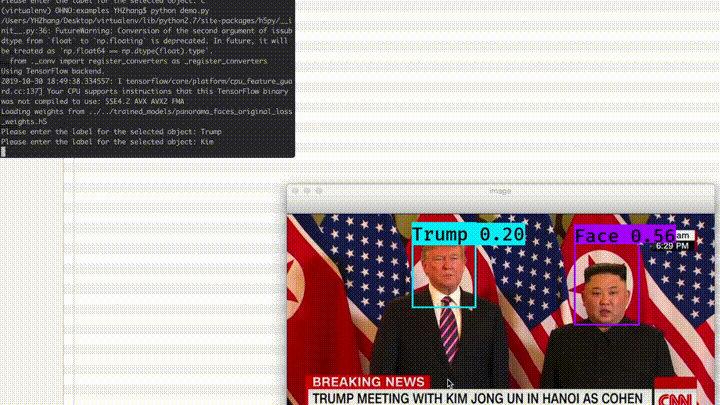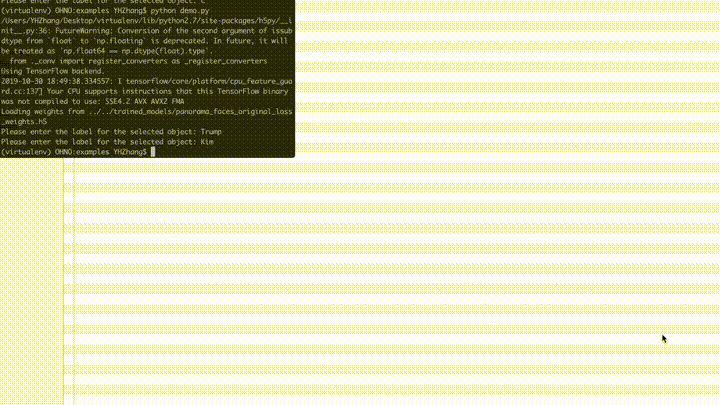
The demo below can demonstrate a typical use case and the capability of Panorama. Say a journalist or a mall security staff wants to expand the vocabulary of Panorama. She can click on the faces, give a label, and from then on, Panorama starts to know the name and do the job. Everything was on-the-fly, and no deep nets training was involved.