Use graph data management systems to scale Graph Neural Networks
This post is about our project Lotan and paper: Lotan: Bridging the Gap between GNNs and Scalable Graph Analytics Engines, published at VLDB 2023. Please check the home page here and the code release here. This work is co-authored with Arun Kumar.
We have been in the current technical explosion of AI/ML for over a decade. Neural networks have completely changed the landscape of many application tasks, from recognizing objects in photos to generalizing convincing, human-like speech or painting art based on people’s requests. Text, images, videos, tables, you can throw all kinds of data to neural networks, and they do the job for you.
Graph data is no exception; neural networks can also be modified to work on them. What is it called when you use a neural network on a graph? It’s called a Graph Neural Network (GNN). It may sound unassuming–after all, just another data modality on the path of modern AI/ML’s remarkable conquering. People assumed the same infrastructure and systems used to scale up NN workloads could also be extended to accommodate GNNs. But don’t be fooled. GNNs are actually some of the most challenging workloads to execute and scale. Consequently, GNN system research has been a heated research topic in the past few years, and many problems remain unsolved to this day.
What makes GNNs so difficult?
Graph data are irregularly shaped and non-IID, differentiating them from regular IID data modalities such as text and images, for which the state-of-art DL frameworks were designed. Most DL frameworks employ distributed data-parallel schemes to tackle data scalability issues. However, data parallelism does not directly apply to graph data.
The common GNNs have two components: the graph part and the neural network part. The NNs are mostly standard ML methods: MLP, RNN, Attention, etc., all easily supported with existing infrastructures. The tricky part is the graph-data-specific operations. It turns out they are entirely different beasts and cause tons of trouble: when you partition a graph, the partitions remain correlated. You can never operate on them truly independently. Therefore, graphs are more challenging to process in parallel.
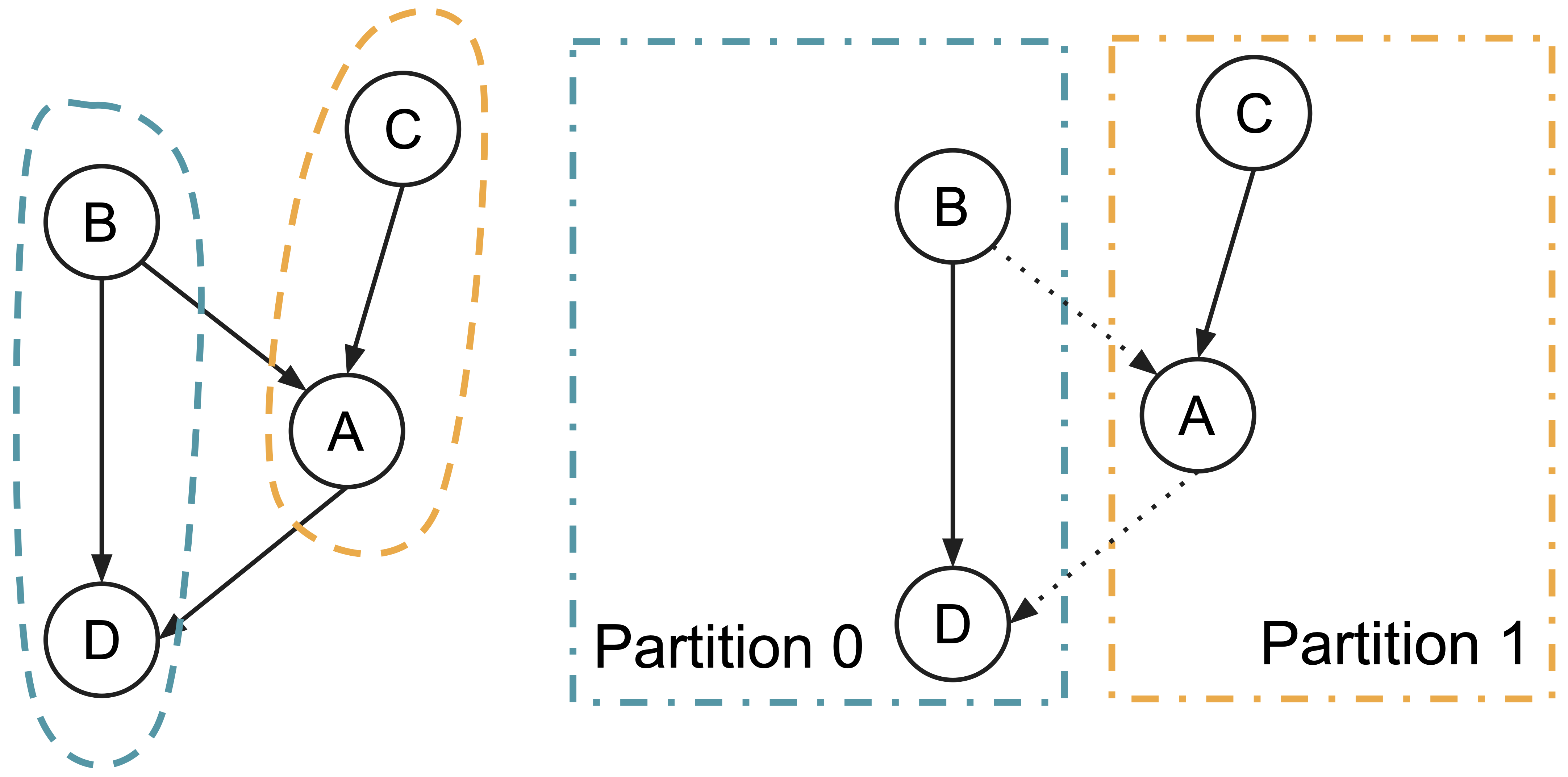
Consequently, the training process of GNNs now involves cross-partition communications, depending on the input graph structure.
This is especially bad when we want to scale the workload by throwing in more computational nodes. More data partitions would mean more cross-partition communications, and we have severely impacted scalability.
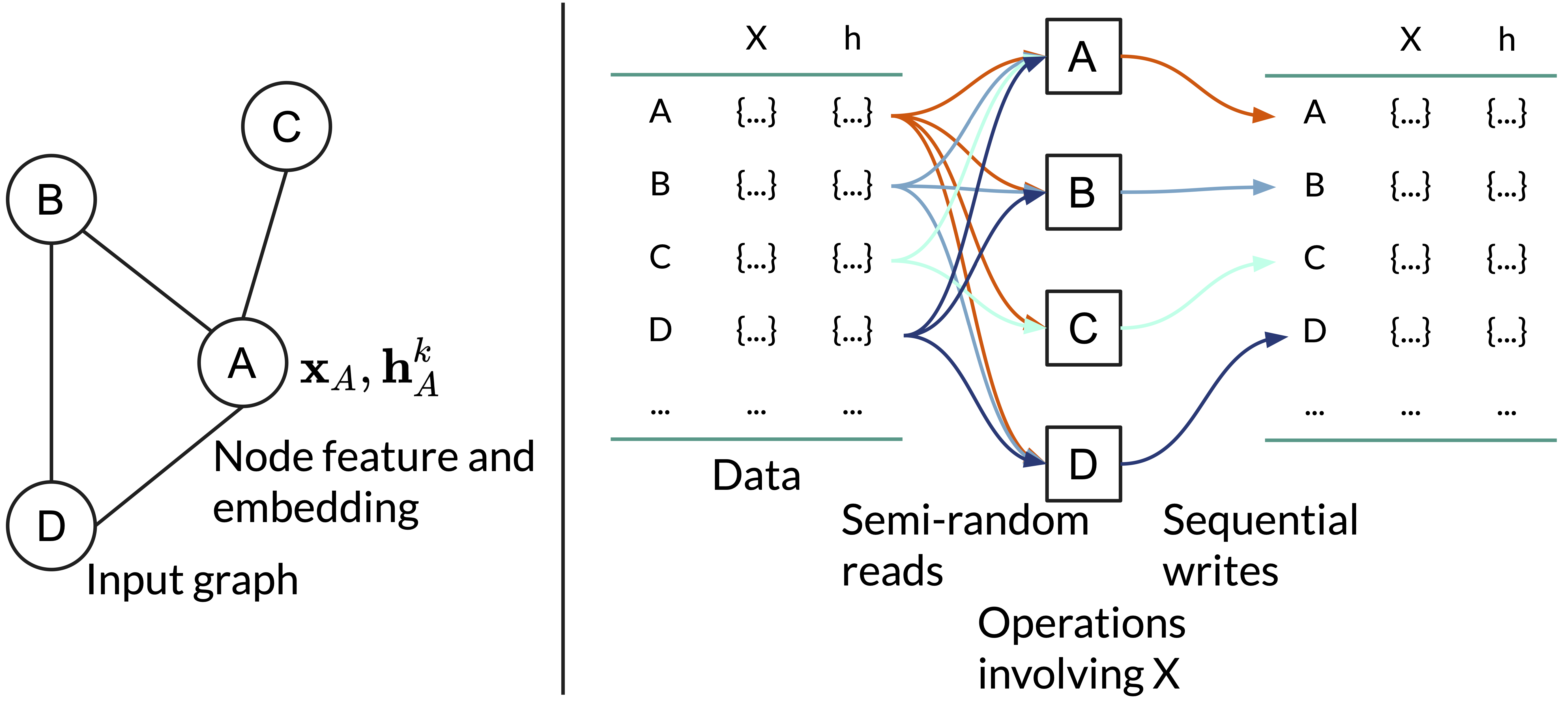
The second challenge comes from the neural network. NN backpropagation requires caching intermediate data during forward propagation. Depending on the graph data, these intermediates could be huge in size. Unlike models such as CNNs or Transformers designed for IID data, where input shape is often normalized and uniform, GNNs are highly input-dependent. They are therefore tough to accommodate, as workloads are highly versatile and vary significantly in scale.
GNN = G + NN
To scale GNN workloads, existing systems take a somewhat brute-force approach: they would cast the GNN operations as huge matrix multiplications and throw them to DL frameworks using GPUs. When GPU memory is insufficient to host the entire matrices and the intermediate results, they either resort to distributed processing of big matrix multiplications and/or spilling techniques that load/offload data from GPU accordingly.
However, as you may have already realized, the biggest GNN systems challenges are, in fact, challenges of managing, moving, and handling the underlying graph data. Nonetheless, existing custom GNN systems mix the graph data and DL challenges and couple them together. There are several major shortcomings: First, many of these systems reinvent the wheel of much work done in the database world on scalable graph analytics engines, which were explicitly designed to tackle these graph data management challenges. Second, the existing systems often tightly couple the scalability treatments of graph data processing with that of GNN training, resulting in entangled, complex problems and systems that often do not scale well on one of those axes.
GNN meets Graph DB
Interestingly, GNN workloads, though drastically different from regular DNN workloads in data access patterns, are not too far away from non-NN graph analytics such as PageRank. In fact, most of the popular GNNs can be expressed under extended versions of graph programming models such as Gather-Apply-Scatter (GAS). Scaling shallow graph analytics is not new; many graph data systems were designed for that purpose. However, none of these graph analytics systems provide general GNN support, nor do they handle DL operations, which, nowadays, are better reserved for frameworks such as TensorFlow and PyTorch.
Eureka moment! How about we use both a scalable graph system and a DL framework? We employ graph systems for graph challenges and DL systems for DL challenges. The benefits are obvious; this divide-and-conquer approach can combine the benefits from both worlds and provide the decoupling of graph and neural networks, analogous to the famous decoupling of compute and storage. The two components can now scale independently of each other: when you increase the graph-side workload, such as working on a larger graph, you only need to increase graph processing power. Similarly, when you increase the size of NN, you only need to think about the NN, and no need to worry if the graph processing would mysteriously crash, as in the other GNN systems with entangled graph and NN operations.
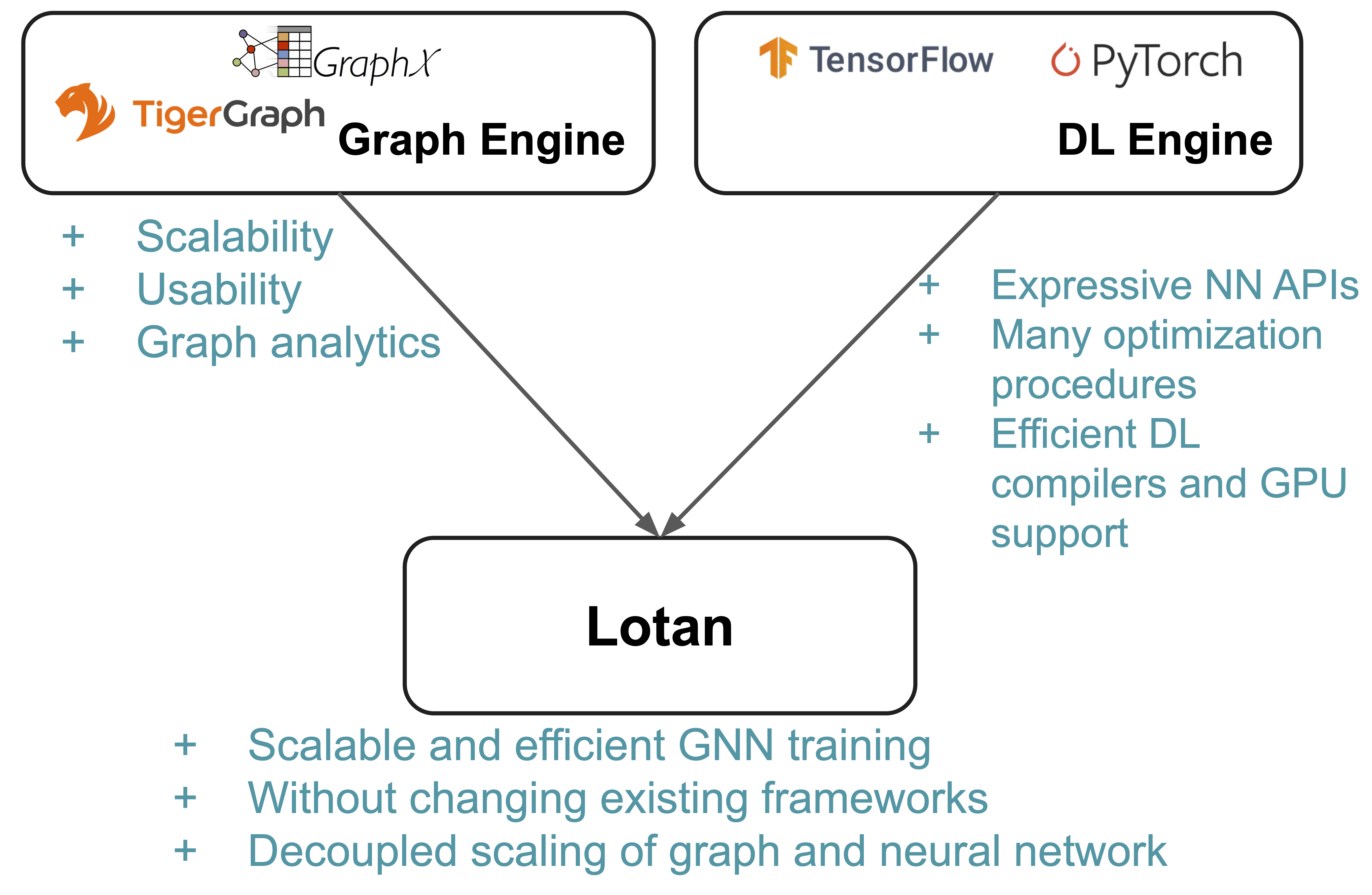
We have built a prototype based on Spark GraphX and PyTorch, called Lotan, with a feat of technical novelties and engineering efforts to make it as efficient and scalable as possible without modifying the codebase of either GraphX or PyTorch. Furthermore, such an architecture allows the user to run GNNs directly from their Graph DB, and the system can piggy pack all the useful functionalities such as fault tolerance, general data management capabilities, and transactions that a mature graph data system can offer. Check our paper to see the details of all the innovations, including Planner Optimization, GNN-centric Graph Partitioning, GNN Model Batching, and many more.
Takeaways
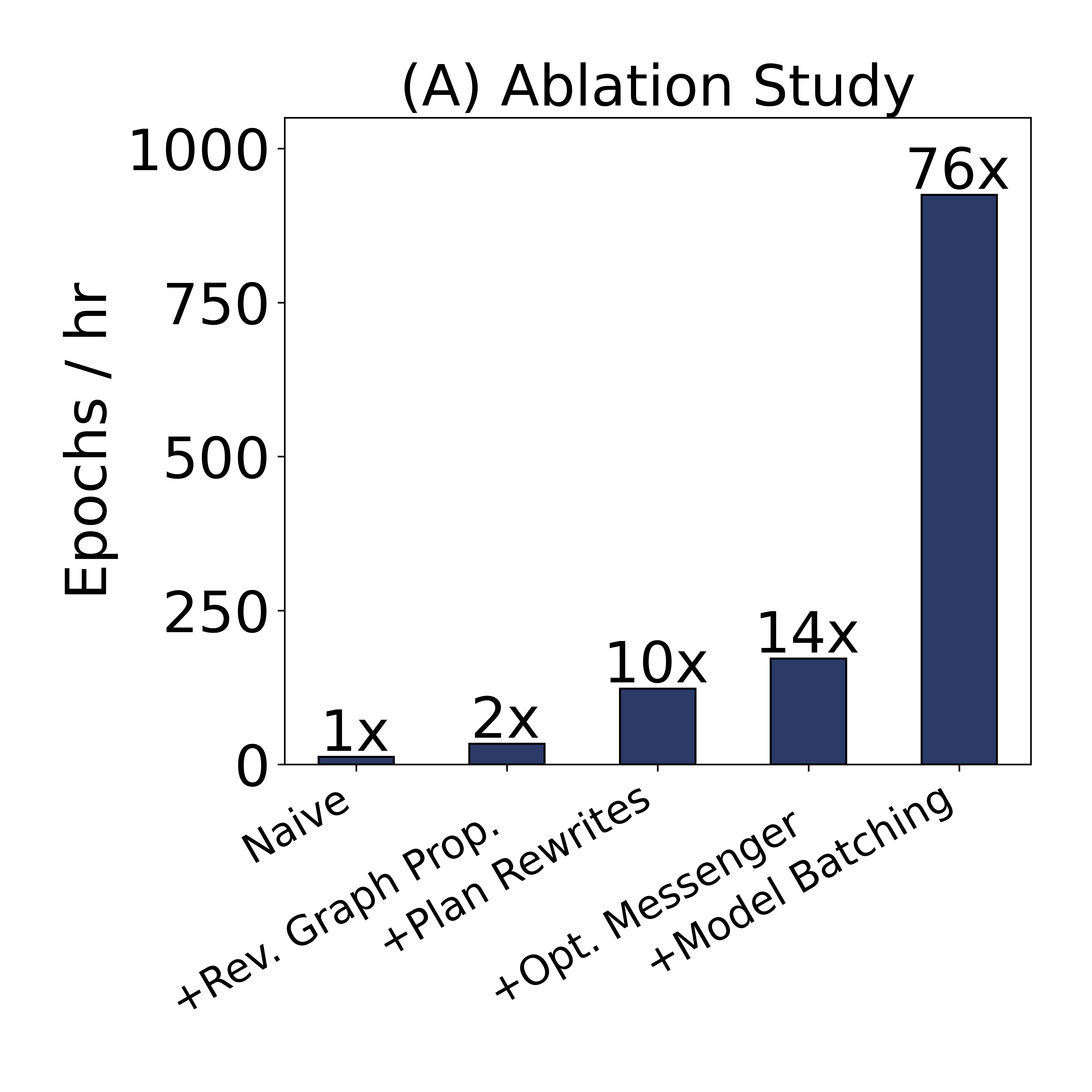
In the paper, we did various tests against prior art and various drill-down tests measuring scalability, resource utilization, etc. Here is a snippet from the ablation study. We achieved a 76x speed-up over a naive in-database GNN system implementation!
- We showed that our system is the most scalable distributed GNN system among the ones we tested against: DistDGL, AliGraph, and Sancus. It can also provide the best accuracy while offering speed-ups on many workloads.
- It is possible to apply existing graph analytical infrastructure to GNN workloads, and it can provide scalability benefits.
- We have shown the system’s cool capabilitiess of scaling to full-graph training with: billion-edge graphs, models with 100M parameters, 16-layer GNN with dense MLPs, and many more. Check our paper for the details!